
Originally published on the UK Web Archive blog on the 20th November 2015.
Over the last few years, it’s been wonderful to see more and more researchers taking an interest in web archives. Perhaps we’re even teetering into the mainstream when a publication like Forbes carries an article digging into the gory details of how we should document our crawls in How Much Of The Internet Does The Wayback Machine Really Archive?
Even before the data-mining BUDDAH project raised these issues, we’d spent a long time thinking about this, and we’ve tried to our best to capture as much of our own crawl context as we can. We don’t just store the WARC request and response records (which themselves are much better at storing crawl context than the older ARC format), we also store:
- The list of links that the crawler found when it analysed each resource (this is a standard Heritrix3 feature).
- The full crawl log, which records DNS results and other situations that may not be reflected in the WARCs.
- The crawler configuration, including seed lists, scope rules, exclusions etc.
- The versions of the software we used (in WARC Info records and in the PREMIS/METS packaging).
- Rendered versions of original seeds and home pages, as PNG and as HTML, and associated metadata.
In principle, we believe that the vast majority of questions about how and why a particular resource has been archived can be answered by studying this additional information. However, it’s not clear how this would really work in practice. Even assuming we have caught the most important crawl information, reconstructing the history behind any particular URL is going to be highly technical and challenging work because you can’t really understand the crawl without understanding the software (to some degree at least).
But there are definitely gaps that remain - in particular, we don’t document absences well. We don’t explicitly document precisely why certain URLs were rejected from the crawl, and if we make a mistake and miss a daily crawl, or mis-classify a site, it’s hard to tell the difference between accident and intent from the data. Similarly, we don’t document every aspect of our curatorial decisions, e.g. precisely why we choose to pursue permissions to crawl specific sites that are not in the UK domain. Capturing every mistake, decision or rationale simply isn’t possible, and realistically we’re only going to record information when the process of doing so can be largely or completely automated (as above, see also You get what you get and you don’t get upset).
And this is all just at the level of individual URLs. When performing corpus analysis, things get even more complex because crawl configurations vary within the crawls and change over time. Right now, it’s not at all clear how best to combine or summarize fine-grained provenance information in order to support data-mining and things like trend analysis. But, in the context of working on the Buddha project, we did start to explore how this might work.
For example, the Forbes article brings up the fact that crawl schedules vary, and so not every site has been crawled consistently, e.g. every day. Of course, we found exactly the same kind of thing when building the Shine search interface, and this is precisely why our trend graphs currently summarize the trends by year. In other words, if you average the crawled pages by year, you can wash out the short-lived variations. Of course, large crawls can last months, so really you want to be able to switch between different sampling parameters (quarterly, six-monthly, or annual, starting at any point in the year, etc.), so that you can check whether any perceptible trend may be a consequence of the sampling strategy (not that we got as far as implementing that, yet).
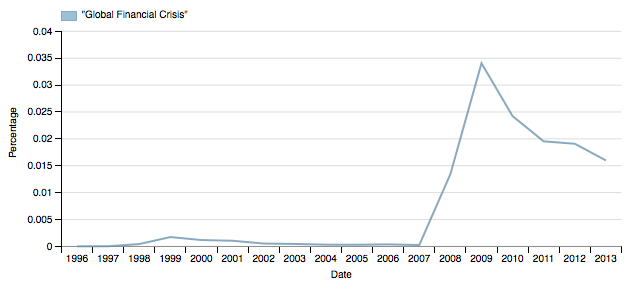
Similarly, notice that Shine show you the percentage of matching resources by year, rather than the absolute number of matching documents. This is because showing the fraction of the crawled web that matches your query is generally more useful than just the number of matching resources because in the latter case the crawl scheduling tends to obscure what’s going on (again, it would be even better to be able to switch between the two so you can better understand what any given trend means, although if you download the data for the graph you get the absolute figures as well as the relative ones).
More useful still would be the ability to pick any other arbitrary query to be the normalization baseline, so you could plot matching words against total number of words per year, or matching links per total number of links, and so on. The crucial point is that if your trend is genuine, you can use sampling and normalization techniques to test that, and to find or rule out particular kinds of biases within the data set.
This is also why the trend interface offers to show you a random sample of the results underlying a trend. For example, it makes it much easier to quickly ascertain whether the apparent trend is due to a large number of false-positive hits coming from a small number of hosts, thus skewing the data.
I believe there will be practical ways of summarizing provenance information in order to describe the systematic biases within web archive collections, but it’s going to take a while to work out how to do this, particularly if we want this to be something we can compare across different web archives. My suspicion is that this will start from the top and work down - i.e. we will start by trying different sampling and normalization techniques, and discover what seems to work, then later on we’ll be able to work out how this arises from the fine details of the crawling and curation processes involved.
So, while I hope it is clear that I agree with the main thrust of the article, I must admit I am a little disappointed by it’s tone.
If the Archive simply opens its doors and releases tools to allow data mining of its web archive without conducting this kind of research into the collection’s biases, it is clear that the findings that result will be highly skewed and in many cases fail to accurately reflect the phenomena being studied.
Kalev Leetaru, How Much Of The Internet Does The Wayback Machine Really Archive?
The implication that we should not enable access to our collections until we have deduced their every bias is not at all constructive (and if it inhibits other organisations from making their data available, potentially quite damaging).
No corpus, digital or otherwise, is perfect. Every archival sliver can only come to be understood through use, and we must open up to and engage with researchers in order to discover what provenance we need and how our crawls and curation can be improved.
There are problems we need to document, certainly. Our BUDDAH project is using Internet Archive data, so none of the provenance I listed above was there to help us. And yes, when providing access to the data we do need to explain the crawl dynamics and parameters - you need to know that most of the Internet Archive crawls omit items over 10MB in size (see e.g. here), that they largely obey robots.txt (which is often why mainstream sites are missing), and that right now everyone’s harvesting processes are falling behind the development of the web.
But researchers can’t expect the archives to already know what they need to know, or to know exactly how these factors will influence your research questions. You should expect to have to learn why the dynamics of a web crawler mean that any data-mined ranking is highly unlikely to match up the the popularity as defined by Alexa (which is based on web visitors rather than site-to-site links). You should expect to have to explore the data to test for biases, to confirm the known data issues and to help find the unknown ones.
“Know your data” applies to both of us. Meet us half way.
What we do lack, perhaps, is an adequate way to aggregating these experiences so new researchers do not have to waste time re-discovering and re-learning these things. I don’t know exactly what this would look like, but the IIPC Web Archiving Conferences provide a strong starting point and a forum to take these issues forward.