- Blog/
Updating our historical search service

Originally published on the UK Web Archive blog on the 15th of February 2016.
Earlier this year, as part of the Big UK Domain Data for the Arts and Humanities project, we released our first ‘historical search engine’ service. We’ve publicised it at IDCC15, the 2015 IIPC GA and at the first RESAW conference, and it’s been very well received. Not only has it lead to some excellent case studies that we can use to improve our services, but other web archives have shown interest in re-using the underlying open source code. In particular, some of our Canadian colleagues have successfully launched webarchives.ca, which lets users search ten years worth of archived websites from Canadian political parties and political interest groups (see here for more details).
But we remained frustrated, for two reasons. Firstly, when we built that first service, we could not cope with the full scale of the 1996-2013 dataset, and we only managed to index the two billion resources up to 2010. Secondly, we had not yet learned how to cope with more than one or two users at a time, so we were loath to publicise the website too widely in case it crashed. So, over the last six months, and with the guidance of Toke Eskildsen and Thomas Egense at the State Library of Denmark, we’ve been working on resolving these scaling issues (their tech blog is definitely worth a look if you’re into this kind of thing).
Thanks to their input, I’m happy to be able to announce that our historical search prototype now spans the whole period from 1996 to the 6th April 2013, and contains 3,520,628,647 distinct records.
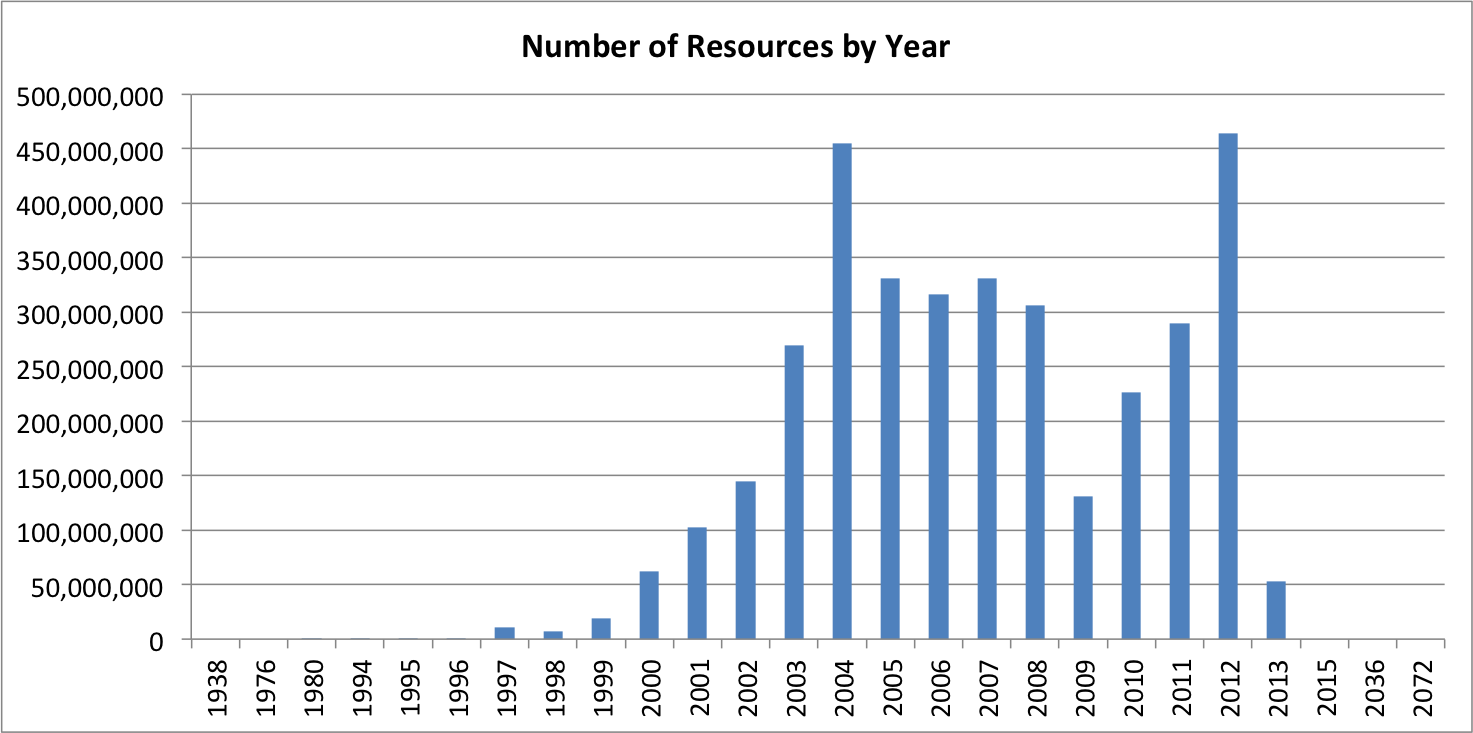
Broken down by year, you can see there’s a lot of variation, depending on the timings of the global crawls from which this collection was drawn. This is why our trends visualisation plots query results as a percentage of all the resources crawled in each year rather than absolute figures. However, the overall variation and the fact that the 2013 chunk only covers the first three months should be kept in mind when interpreting the results.
You might also notice there seem to be a few data points from as early as 1938, and even from 2072! This tiny proportion of results correspond to malformed or erroneous records, although currently it’s not clear if the 1,714 results from 1995 are genuine or not. No one ever said Big Data would be Clean Data.
Furthermore, we’ve decided to change the way we handle web archiving records that have been ‘ de-duplicated’. When the crawler visits a page and finds precisely the same item as before, instead of storing another copy, we can store a so-called “revisit record” and refer to the earlier copy rather than duplicating it. This crude form of data compression can save a lot of disk space for frequently crawled material, and it’s use has grown over time. For example, looking at the historical dataset, you can see that 30% of the 2013 results were duplicates.
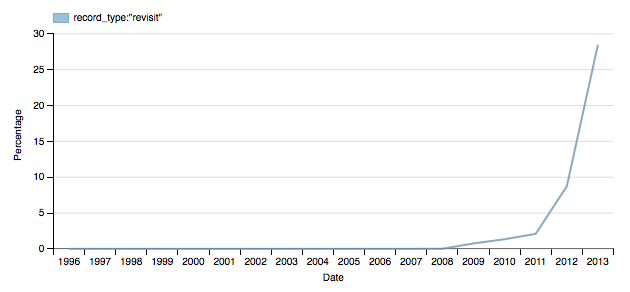
However, as these records don’t hold the actual item, our indexing process was not able to index these items properly. Over the next few weeks, we shall scan through these 65 million revisit records and ‘reduplicate’ them. This does mean that, for now, the results from 2013 might be a bit misleading in some cases. We also failed to index the last 11,031 of the 515,031 WARC files that make up this dataset (about 2% of the total, likely affecting the 2010-2013 results only), simply because we ran out of disk space. The index is using up 18.7TB of SSD storage, and if we can find more space, we’ll fill in the rest.
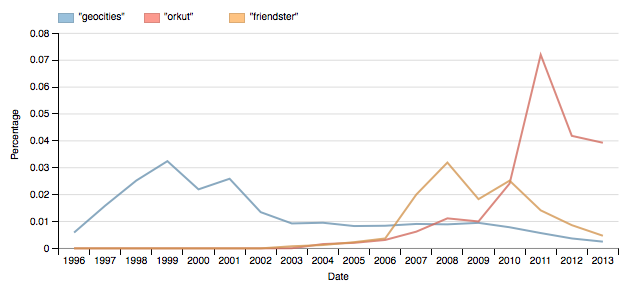
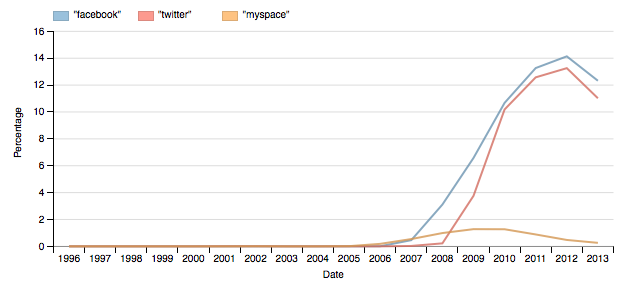
In the meantime, please explore our historical archive and tell us what you find! It might be slow sometimes (maybe 10-20 seconds), so please be patient, but we’re pretty confident that it will be stable from now on.
Anj