
Every so often, there’s some publication or panel that worries about all that data out there. Claims are made about how many exa-lorra-huge-o-bytes are lurking in all the corners of the world. Claims which, if they can be traced at all, usually end up coming from the marketing bumf pumped out by storage vendors. These big numbers are waved around, and we revel in the impossibility of capturing it all. Sometimes, they become a kind of white flag, a justification for giving up.
Look, I enjoy that kind of grandiose discussion as much as anyone, and big numbers probably help grab headlines. But I also think they draw the eye away from the real issues.
Societies have always generated far more information than they preserve. The common communications of yesteryear have moved from analogue to digital, but that doesn’t suddenly means we should expect to keep it all. Any more that we should worry about having enough shelf space for all the notebooks and diaries in the world’s drawers.
We already have cultural memory machines, whose very purpose is to decide what to keep. Libraries. Archives. Museums. Galleries. And the rest.
Rather than swooning over the volume of information swooshing about out there, I’m more interested in understanding what’s changed at the interfaces between society and our shared memory machines. Getting into the details, rather than just looking at the numbers,
How are our memory machines coping? How is the digital transformation of our societies affecting the ability of our institutions to do their work? Where are the gaps? What isn’t being preserved because it isn’t clear which institution can or should be doing it? Do people even know or care about our digital memory machines?
To me, these are the really compelling questions. Things with enough context to be evidenced, and actioned.
Evidence of Invisibility#
This graph from a 2017 analysis shows the annual income of the British Library, corrected for inflation.
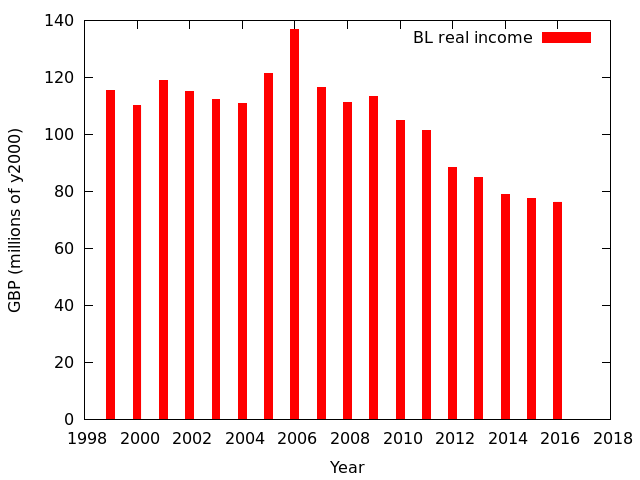
During this period, the library went from being a print collection with a handful of digital services to a hybrid collection with many different digital services, and with the responsibility to preserve the UK’s digital output as well as print.
By looking at that graph, can you tell which year the library started to grow by around one hundred terabytes of data per year? With the expectation that billions of items would be findable and made available while operating under a complex set of legally-defined technical constraints entirely specific to this singular context?
It was 2013. There in the middle of that downward curve.
Today, the library manages petabytes of data and has the responsibility of providing nation-scale digital memory, on funds that have only ever shrunk.
While the details may differ, this situation is not unique to the British Library. It applies to almost every cultural heritage insitution. No wonder we’re struggling to adapt. No wonder the digital work meets resistance, at times verging on a kind of immune-system response.
It was the reaction to the 2023 British Library cyberattack that really brought the invisibility of digital heritage home to me. While the library has been admirably open about what happened and the British press has been uncharacteristically supportive, it is remarkable how little has been said about the library’s digital collections. The lost reading rooms and catalogues were rightly lamented and prioritized. But I didn’t see a single article ask a single question about our digital heritage. eBooks were mentioned once. A tiny sliver of the library’s digital treasures.
I think this invisibility is the biggest preservation risk there is. If digital heritage isn’t seen or valued, how can we hope to push back against the endless grinding down of funding and ambition?
I fear waving around large numbers just isolates us from those who fund us. Perhaps there are better questions to ask? Perhaps there are ways to show the digital is loved too?