In 2012, JISC funded two projects based on the idea of exploring the ways in which researchers might exploit the JISC UK Web Domain Dataset (1996-2013).
The Analytical Access to the Dark Domain Archive project built our first historical search service, and helped us to understand the issues around providing rich interfaces and search capabilities on large-scale collections. You can find out more about the project by visiting the IHR AADDA project page or by reading the project blog.
The Big Data (Demonstrating the Value of the UK Web Domain Dataset for Social Science Research) project took a different approach. Rather than building a user interface and providing a search service, the raw data was passed to the researchers in order to see how they might best exploit it using their own infrastructure and capabilities. This led to the publication of a conference paper at the WebSci'14 conference. For more information, you can refer to the OII project page.
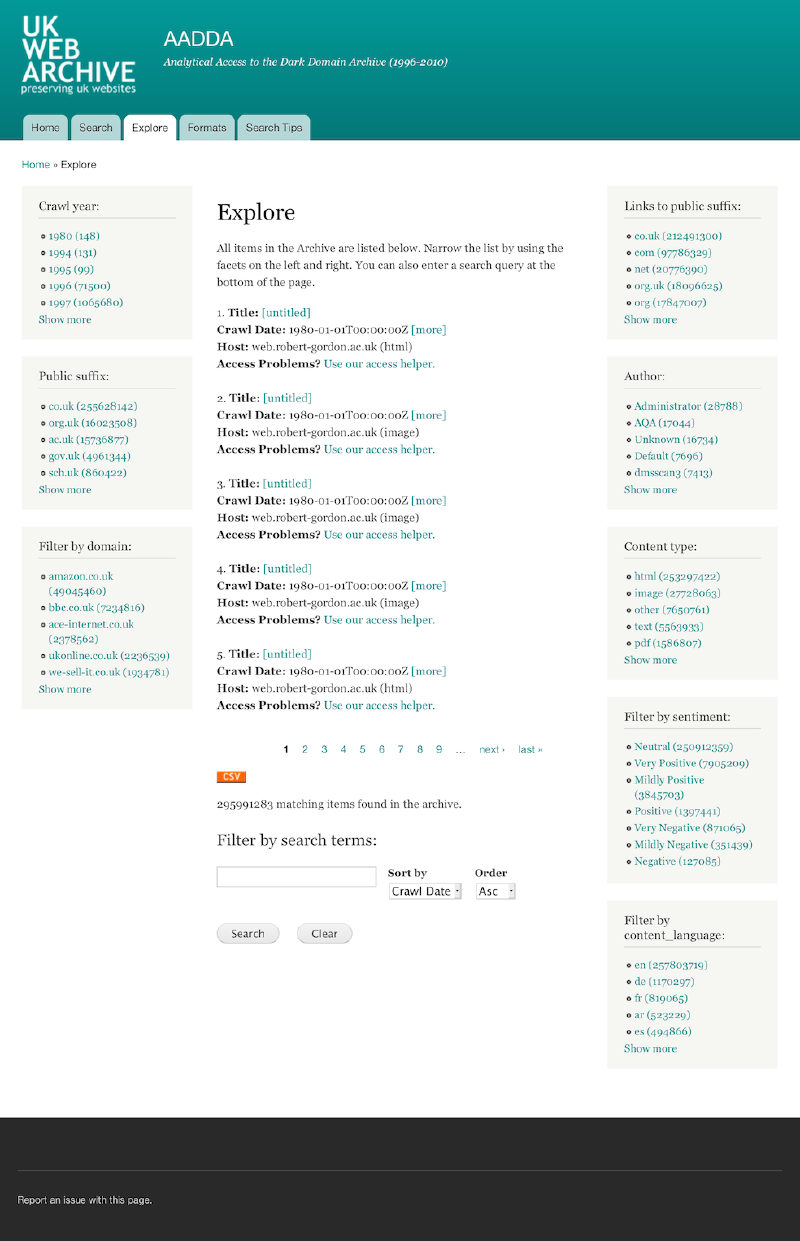
I led the technical development of the AADDA service. I began learning how to scale Apache Solr from millions to hundreds of millions of resources, and started building up our open source code base for indexing web archives. I also developed our initial user interface based on Drupal Sarnia (as shown here).
The work we began in AADDA was later continued under the BUDDAH project.