
First published as this UK Web Archive blog post.
This is a summary of what’s been going on since the 2023 Q2 report.
Replication#
The most important achievement over the last quarter has been establishing a replica of the UK Web Archive holdings at the National Library of Scotland (NLS). The five servers we’d filled with data were shipped, and our NLS colleagues kindly unpacked and installed them. We visited a few weeks later, finishing off the configuration of the servers so they can be monitored by the NLS staff and remotely managed by us.
This replica contains 1.160 PB of WARCs and logs, covering the period up until February 2023. But, of course, we’ve continued collection since then, and including the 2023 Domain Crawl, we already have significantly more data held at the British Library (about 160 TB more, ~1.3 PB in total). So, the next stage of the project is to establish processes to monitor and update the remote replica. Hopefully, we can update it over the internet rather than having to ship hardware back and forth, but this is what we’ll be looking into over the next weeks.
The 2023 Domain Crawl#
As reported before, this year we are running the Domain Crawl on site. It’s had some issues with link farms, which caused the number of domains to leap from around 30 million to around 175 million, which crashed the crawl process.
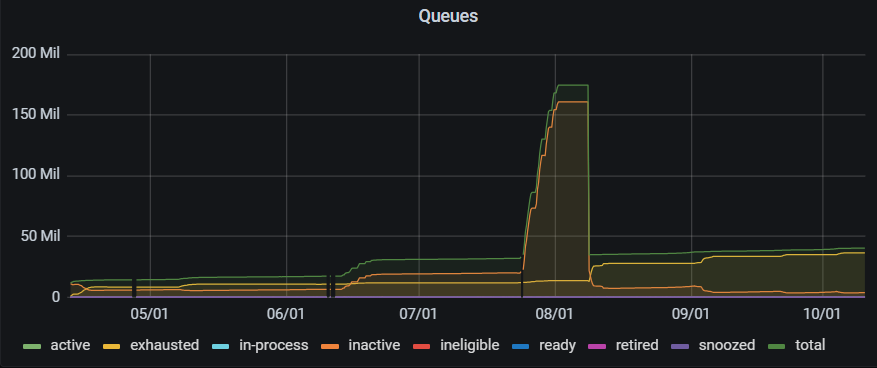
However, we were able to clean up and restart it, and it’s been stable since then. As of the end of this quarter we’ve downloaded 2.8 billion URLs, corresponding to 183 TB of (uncompressed) data.
Legal Deposit Access Service#
We’ve continued to work with Webrecorder, who have added citation, search and print functionality to the ePub reader part of the Legal Deposit Access Service. This has been deployed and is available for staff testing, but we are still resolving issues around making it available for realistic testing in reading rooms across the Legal Deposit Libraries.
Browsertrix Cloud Local Deployment#
We have worked out most of the issues around getting Browsertrix Cloud deployed in a way that complies with Non-Print Legal Deposit legislation and with our local policies. We are awaiting the 1.7.0 release which will include everything we need to have a functional prototype service.
Once it’s running, we can start trying our some test crawls, and work on how best to integrate the outputs into our main collection. We need some metadata protocol for marking crawls as ready for ingest, and we need to update our tools to carefully copy the results into our archival store, and support using WACZ files for indexing and access.