
Abstract#
Under Legal Deposit, our crawl capacity needs grew from a few hundred time-limited snapshot crawls to the continuous crawling of hundreds of sites every day, plus annual domain crawling. We have struggled to make this transition, as our Heritrix set-up was cumbersome to work with when running large numbers of separate crawl jobs, and the way it managed the crawl process and crawl state made it difficult to gain insight into what was going on and harder still to augment the process with automated quality checks. To attempt to address this, we have combined three main tactics; we have moved to containerised deployment, reduced the amount of crawl state exclusively managed by Heritrix, and switched to a continuous crawl model where hundreds of sites can be crawled independently in a single crawl. These changes have significantly improved the quality and robustness of our crawl processes, while requiring minimal changes to Heritrix itself. We will present some results from this improved crawl engine, and explore some of the lessons learned along the way.
Introduction#
Since we shifted to crawling under Legal Deposit in 2013, the size and complexity of our crawling has massively increased. Instead of crawling a handful of sites for limited periods, we have hundreds of sites to crawl every day, and a domain crawl to perform at least once a year. But the technical team isn’t any bigger than it was before, and the QA team isn’t any bigger than before. So, while we’re sticking with Heritrix as our core crawl engine, we’ve been experimenting with a range of modifications to it (and our supporting systems) over the last year, with the following goals in mind:
- High level of automation
- High level of transparency
- Capture JavaScript-heavy web pages
- Stable domain crawls
- Continuous crawling
Our highest priority is automation of any and all automatable tasks, and where necessary, changing Heritrix to make common tasks easier to automate. Crucially, this includes automating recovery from common errors and outages, such as network outages, server maintenance, etc.
However, when we can’t resolve issues automatically, we need to be able to tell what’s going on. The means we need to be able to monitor progress easily, and be able to inspect what the crawler has been doing so we can debug problems. With this in mind, we’ve done quite a lot of work modifying Heritrix to be less of a ‘black box’ by moving or cloning data usually managed by Heritrix into external systems.
As we’ve discussed at previous conferences, we need to be able to cope with JavaScript-heavy websites by integrating browser-based crawling into the crawl process. We’ve been doing that for a while, but it’s only recently that we’ve really been able to see the benefits.
Even when all that is working fine, we’ve had repeated problems ensuring long, large crawls are stable, so we’ve also spent time looking at that over the last year. If you’d like to hear about the twelve-year-old Heritrix bug I managed to reproduce and resolve during all this, or indeed about any of these other areas, please come and talk to me later on.
However, in this presentation I’d like to focus on the work we’ve done to enable us to use Heritrix to perform continuous crawls.
Continuous Crawling#
One of the most significant changes under Legal Deposit is the need for continuous crawling, and the case of news sites is particularly crucial. Under selective archiving, we might choose one or two news articles a day to archive. Now, we are expected to get the latest news from all UK news sites at least once a day, and ideally more often than that.

But in terms of automation, we found having hundreds of different Heritrix crawl jobs has simply not been practical. The way Heritrix works means it’s difficult to manage the available resources effectively if there are lots of small jobs, and the automation of the stopping and starting of crawl jobs becomes very challenging when there are so many.
Batch Crawling#
Therefore (and like many other institutions), we’ve handled all these little jobs are handled using a smaller set of batch crawls. Specifically, we’ve run six crawl streams with different frequencies, and each crawl gets stopped and restarted on that time-scale. For example, the daily crawl launches once a day, at midday, and runs for one day. This means we get the news sites once a day, but also means we never get more than one day’s worth of crawl time on that site. If we want to get a deeper crawl, we need to duplicate the crawl activity in a separate stream (and risk putting too much pressure on the publishers web site), or rely on the domain crawl to pick up everything else (which, as indicated earlier, has not proven reliable).

This has worked okay, but we wanted to improve things further. For example, being restricted to the batch time frames means we can’t harvest sites when our curators would like us to do so. Similarly, the artificially high load created by launching all the daily crawl activity at once makes it difficult to ensure we manage to successfully pass our crawl seeds through the browser-based rendering engine we use.
What we’d rather do is run one big crawl job, where different sites (or different parts of the same site) can be re-crawled at different intervals. But this is not how Heritrix was designed to work, and we met a number of barriers when trying to work this way:
- Stability & restartability
- Quotas & statistics
- Unique URI filtering
Firstly, we need Heritrix to be stable when run for a long time, but also reliably resumable if we do need to stop and restart it for some reason. This may sound obvious, but we’ve met a number of challenges while trying to get this part right!
Secondly, we still want to apply quotas to crawls and monitor statistics, so we need some way to manage or reset this data when we start re-crawling.
Finally, and most significantly in terms of changes to Heritrix, we need to be able to change how it filters out unique URIs as the crawl proceeds.
Already Seen?#
Every crawler has some kind of record that remembers which URLs it’s already seen. Without that, the crawler would constantly crawl and re-crawl common URLs over and over again. We’d have a million copies of the BBC News homepage and barely any of the articles!

A standard Heritrix crawl uses a special and highly efficient data structure called a Bloom filter to do this. This works great for batch crawling: you put in the URLs you’ve dealt with, and if you see the same URI again it will tell you so. But it’s not a database, and so it can’t do anything else. You can’t ask it to ‘forget’ a URL. You can’t ask it when you saw that URL, or what happened last time.
For that kind of detail, you need a real database of some kind. But this database will end up with billions of entries, and we really don’t want to take on any more technologies because managing large databases is hard. If only we had some kind of standard system we already support that indexes what we’ve captured.
A capture index.
Wait…
That seems familiar…#

A capture index is precisely what any web archive playback system needs. We used to do this using big CDX files, but recently we’ve started using a dedicated database in the form of OutbackCDX.
OutbackCDX#
OutbackCDX is a dedicated CDX service built for web archives. It stores just what you need for playback, and is easy to integrate with playback tools. It’s fast, efficient, and because it’s a real database it can be updated and queried in real time, rather than relying on batch updates. In short, it’s awesome, and as there’s likely a few NLA staff members here I’d like to take this opportunity to thank the National Library of Australia for making OutbackCDX openly available.

So, we’ve found that as well as being great for playback, it’s also handy for mid-crawl data, and we already know how to use it and how to manage large indexes. So what does a crawl look like with OutbackCDX in the loop?
(Re)launching a Crawl#
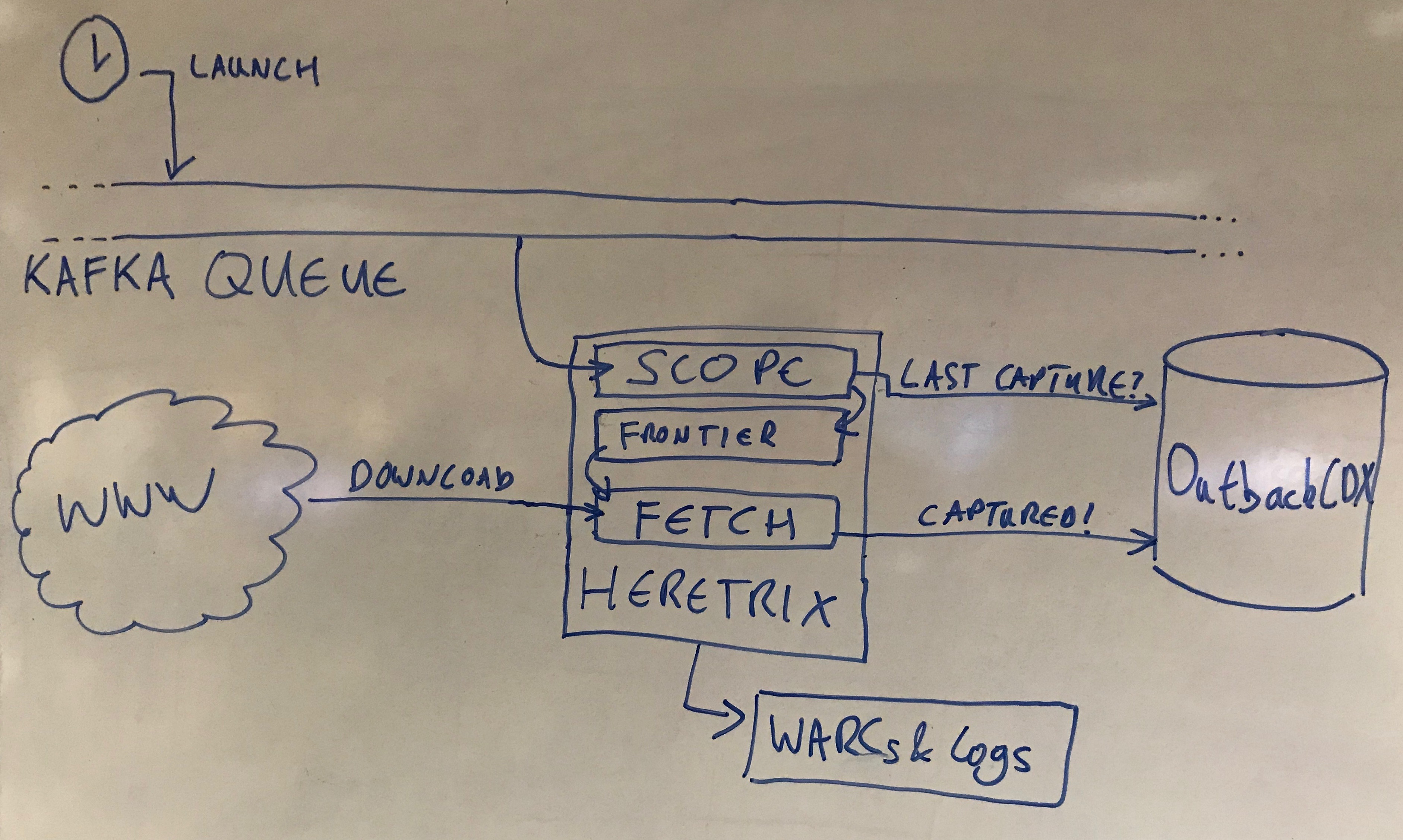
Well, to start the story, we need a new way of launching a crawl. We no longer have individual jobs, so instead we have a single, long-running crawl job that we’ve coupled to a message queue - in our case we’re using Apache Kafka. So, when the time comes, we drop a ’launch’ message on this queue, which the crawl job picks up. It takes the seed URL, and sets up the crawl configuration for that URL using Heritrix’s ‘sheets’ configuration system. This defines the re-crawl frequency (i.e. whether that site should be crawled daily/weekly/etc.) and other parameters like resetting crawl quotas, whether to obey robots.txt and so on.
The seed URL and all subsequent URLs are passed through the usual scoping rules, plus an additional step that calls out to OutbackCDX to see when we last dealt with that URL. This RecentlySeenURIFilter works out how long ago the last crawl was, and if the URL has already been captured within the re-crawl interval. If we have already downloaded the item recently enough, the URL is discarded. However, if a re-crawl is due, it gets enqueued into the Heritrix frontier.
Later, after attempting to download the URL, the crawler registers the outcome in OutbackCDX. The resulting WARCs and log files accumulate as normal, and like any batch crawl material from multiple hosts are stored in a single unified stream of archived resources and metadata.
Advantages#
The approach to continuous crawling has had a number of advantages:
- The One Big Job
- Re-crawl or Refresh?
- Efficient De-duplication
- Real-time Playback
- Access Crawler Screenshots
The main advantage is simply that we crawl the sites the curators want, on the time-scales they have requested. Because this is all done in one large job, this is relatively easy to manage and monitor.
A second advantage comes from a new opportunities this arrangement enables. Because we can set the re-crawl frequency for individual pages and for sections of sites, we can start to explore the possibilities for distinguishing between doing a full re-crawl of a site, and just refreshing parts of a site so we pick up new URLs. We can now easily force the crawler to re-crawl the BBC News homepage in order to pick up new links every few hours, but allow more time for the crawler to pick up the deeper links.
Another plus is that OutbackCDX also stores the checksums of the content downloaded previously, and so can be used to de-duplicate the WARC records and avoid storing multiple copies of resources that haven’t changed. We were already doing this, but using Heritrix’s PersistLog database, which worked well for short crawls but has caused major problems for larger and long-running crawls. Using OutbackCDX for this is much more efficient in terms of disk space requirements, and allows a single deduplication database to be shared between multiple crawlers.
And of course, OutbackCDX is a plain old capture index, so we can also hook up a playback service and use it to inspect the results of the crawl where needed. This works in real-time, with content becoming available immediately after capture.
Finally, OutbackCDX also gives us a handy place to store references to the WARC records that capture what happened when we used the embedded web browsers to capture our seed pages.
Crawler Screenshots#
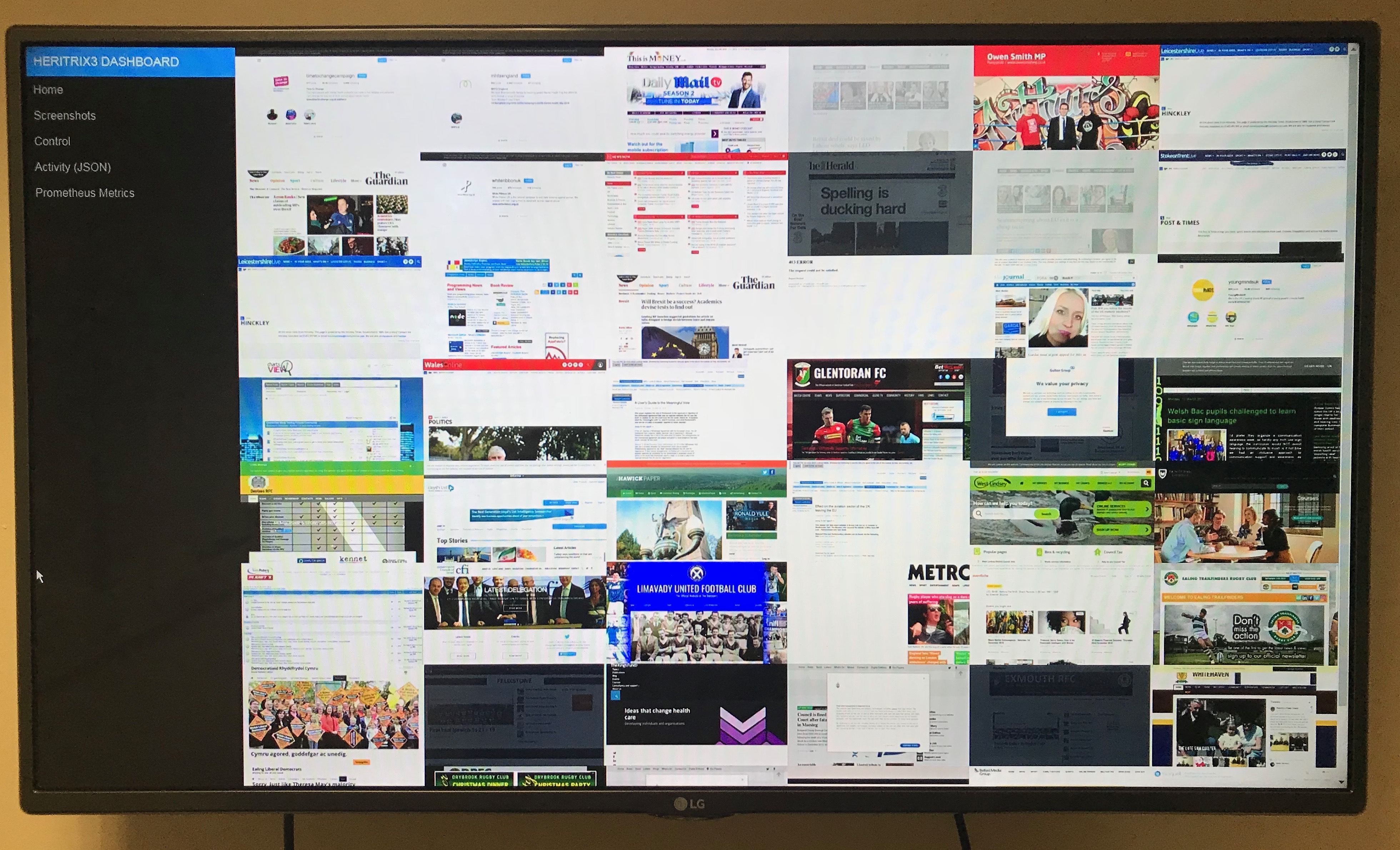
For example, by monitoring activity via the Kafka queues and combining that with information in OutbackCDX, we’ve finally been able to put together a simple dashboard that shows what the browser saw when it rendered the original web sites during the crawl. It’s been great to finally see what the crawler is doing, and makes it easy to spot the kind of problems that lead to blank pages.
Better still, because we’re also running Python Wayback which support HTTPS in proxy mode, we can easily point the rendering service at the archived copy, and re-render what we’ve managed to download in order to compare what we saw with what we got.
For example, here’s a page from the main UK Government publications site, with a strange little difference in the ordering of the entries between the original and the archived version.

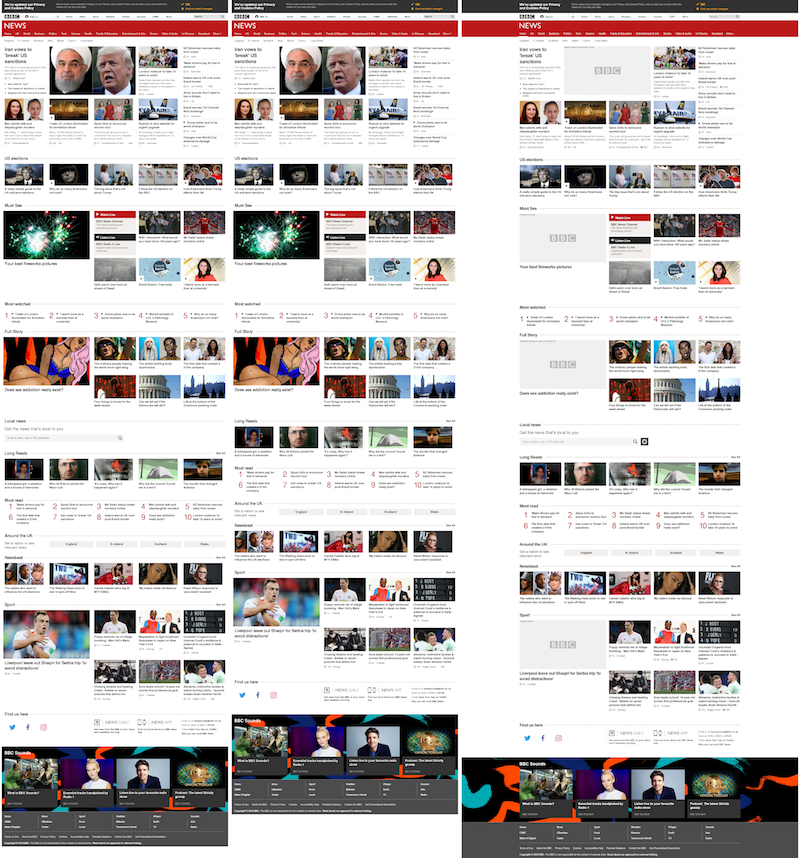
And here’s a BBC News page, showing that we capture full-length screenshots. Here the archived version is extremely similar apart from a couple of minor dynamic changes. It’s not all roses though. If we look at the same page using the usual re-written mode rather than our embedded browser, we start to see some gaps arising from the difference in how the two browsers render the page. So, there’s more work to be done, but nevertheless the quality is much better than it used to be, and we’ve got a way to evaluate the quality of the crawled version, and a better understanding of where the problems are coming from.
Conclusion#
Back at iPres in 2012, Steve Knight gave a deliberately challenging presentation about the kind of cultural change needed to move from hobbyist to artisan and then to industrial-scale digital preservation. I don’t think I really grasped the consequences at the time, but the last five years has shown me that the technical chnages are only one aspect of the broader changes we’ve had to make to how the whole team works, in response to the the scale of the Legal Deposit challenge.
What we’ve seen this year is by making a few careful changes (and fixes) to Heritrix, we’ve been able to radically alter the way we operate our crawls. This new arrangement is more robust, reliable and transparent, requires less manual intervention, and provides the kind of foundation we need in order to explore how we might automate more of our quality assurance work in the future.
However, we’ve also tried to keep these changes fairly modular so that they can be re-used without necessarily changing how you run Heritrix. For example, if you want to use OutbackCDX just for de-duplication, you can. So, if any of this sounds at all interesting, please get in touch so we can learn what kind of components we might be able to share between our institutions.
Thank you.