
Abstract#
The British Library has a long tradition of preserving the heritage of the United Kingdom, and processes for handling and cataloguing print-based media are deeply ingrained in the organisations structure and thinking. However, as an increasing number of government and other publications move towards online-only publication, we are force to revisit these processes and explore what needs to be changed in order to avoid the web archive becoming an massive, isolated silo, poorly integrated with other collection material. We have started this journey by looking at how we collect official documents, like government publications and e-journals. As we are already tasked with archiving UK web publications, the question is not so much ‘how to we collect these documents?’ rather ‘how to we find the documents we’ve already collected?’. Our current methods for combining curatorial expertise with machine-generated metadata will be discussed, leading to an outline of the lessons we have learned. Finally, we will explore how the ability to compare the library’s print catalogue data with the web archive enables us to study the steps institutions and organisations have taken as they have moved online.
This is the script for the presentation I gave as part of Web Archiving Week 2017, on Wednesday 14th of June.
Introduction#
This year, I’ll have worked for the British Library for ten years. But it’s only in this last year that I’ve finally had to get to grips with that quintessential piece of library technology… The Catalogue.
We needed to bring the catalogue and the web archive closer together, linking the traditional cataloguing process to the content from the web. I won’t get into the more technical details here. If you’re interested in that, I’ll be giving a longer presentation on that subject tomorrow morning where I’ll talk about how the implementation worked and how I’m coping with the psychological scarring caused by being exposed to MARC metadata.
Instead, today I want to compare the overall architecture of the two systems, because the web archive and the catalogue manage their data in fundamentally different ways.
The Catalogue#

These are some still frames from a British Library video that shows the journey of a print collection item, from being posted to us, through acquisition, cataloguing, finishing and to the shelf. Then, when a reader requests it, from the shelf and out to the reading room. These processes represent a very large proportion of the day-to-day work of the British Library, and much of the library is built around supporting the efficient ingest and delivery of printed material. I don’t just mean the work of the teams involved, but the very existence of those teams, the roles they hold and the management hierarchies that knit them together. Even the physical structure of our buildings, and the way they are connected, are all shaped by this chain of operations.
At the heart of this process sits the catalogue. At every step, the catalogue is updated to reflect this workflow, with the record of each item being created and then updated along the way. The British Library catalogue is not just a collection of bibliographic metadata, it’s also a process management system.
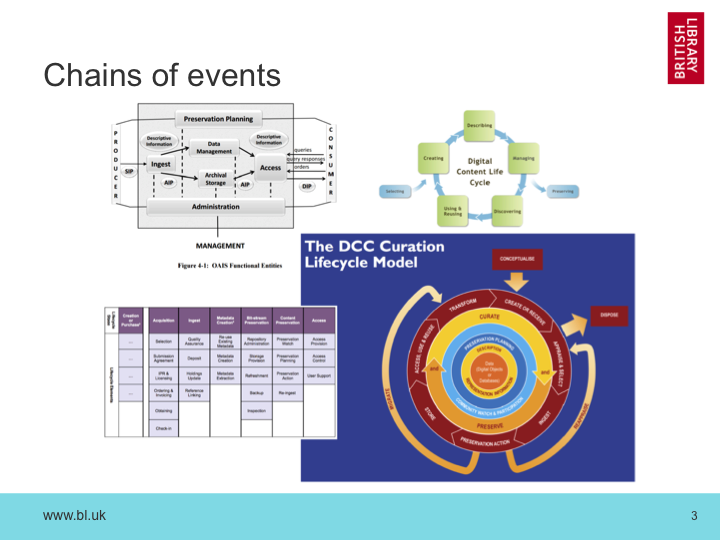
This is a very natural and sensible way to manage the chain of events that must occur in order to deal with print material, and we’ve been doing it like this for a very long time. Consequently, this approach has become deeply embedded in our thinking, and reappears elsewhere. Sometimes the events are in a line, and sometimes in a circle, but always implying a step-by-step approach. Ever forwards.
We found another example last year, when we were looking at the way the library has reacted to the shifting of traditional print publications to online forms, particularly government publications.
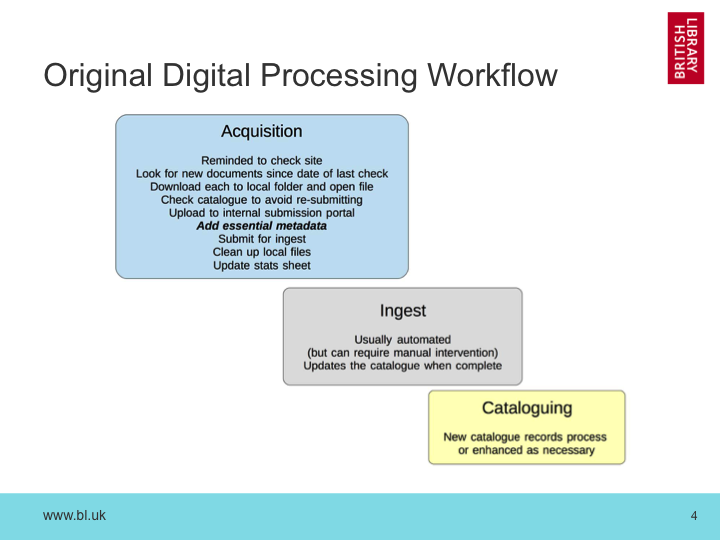
We learned that the curation and cataloging teams that handle printed material had started manually downloading these publications from the web, processing them and submitting them into our digital library system, and recording this all in the catalogue. But these very same publications were being downloaded and stored through our regular web archiving activities. This duplication of content reflected a significant duplication of effort across teams, and so we set out to resolve it by building a document harvester on top of the web archive.
The Web Archive#
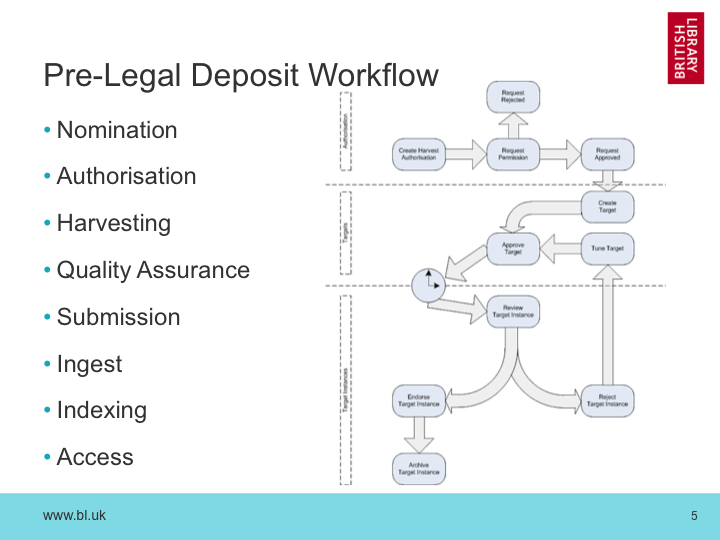
Before legal deposit, the web archive also worked as a chain of events. Every crawl target was defined by a period of time. Usually, we’d crawl a site a few times while we built up a collection, but at some point the crawl target was deemed complete and we’d move on to a new collection and a new set of sites to capture. The Web Curator Tool was built around this process.
But when Legal Deposit came along, this had to change. The most obvious change under Legal Deposit is the sheer scale of the operation, going from thousands of sites a year to millions. But it’s also about the way the workflow has changed.
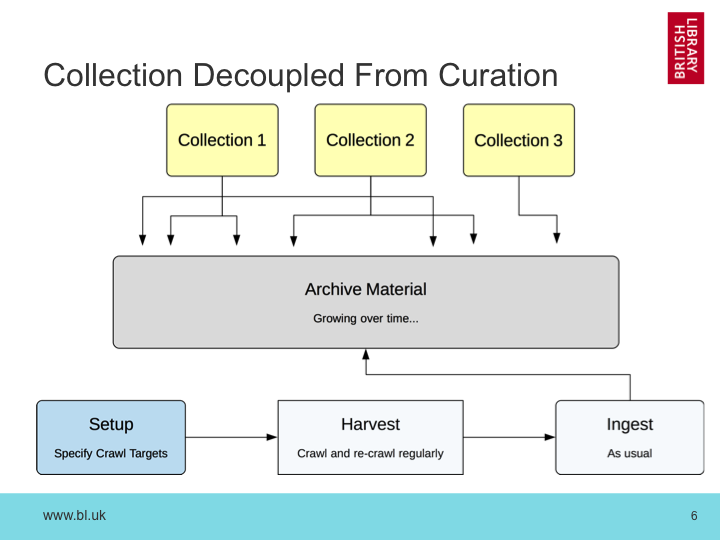
Under Legal Deposit, we have to try to get it all, all the time! One very important example is that we now collect hundreds of news sites every day, because we want to have a good snapshot of web news no matter what, and this is an ongoing effort. We’re not going to stop one day and declare we’ve had enough news (although lately that has become more tempting!).
But of course, we still want to make our web archive more accessible by building collections around specific events or areas of interest. So the curation process now looks rather different. It might mean adding a new set of web sites to be crawled, but it’s more likely to mean pulling in snapshots of sites or specific pages we’ve already crawled. The process of cataloguing and curating the web has become largely de-coupled from the process of collecting the web.
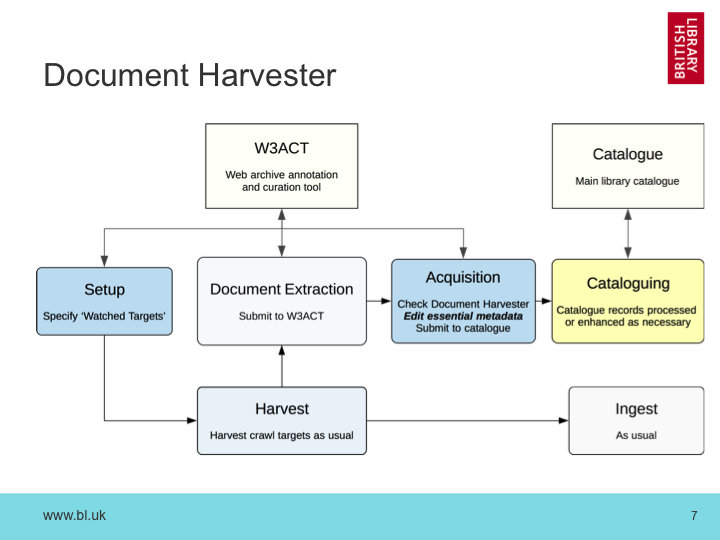
Harvesting documents works in much the same way - rather than launching specific crawls for this purpose, we can pick out documents from the crawls and expose them for cataloguing.
But now we have two systems that hold metadata we need to bring into play when we make our data discoverable and accessible. Somehow we have to knit all these different sources of information together. To make things even more complicated, we have to cope with the fact that some of these processes need to evolve quite rapidly over time. We are still learning how to index our born-digital material, and we need a way to experiment with different tactics without creating a mess of metadata that we can’t unpick.
Bringing them Together#
For print material, our cataloguing standards do change slowly over time, but we accept that you can’t just go back and re-catalogue everything. Because of the manual work involved, updates to the catalogue for print material are rare, and there’s no sense optimising your workflow around rare events. This is why the library focusses on managing items passing through a step-by-step workflow.
But digital is different. Digital means you can go back and re-process everything, and this gives you new ways to bring data together. It’s like suddenly having massive army of dexterous androids to walk the shelves and re-catalogue all the books.
Maybe like this…

Or…

Maybe not.

(it’s surprisingly difficult to find an image of a large group of robots that isn’t creepy)
How does this help us bring disparate data sources together? Well, a good analogy can be found in the recent geo-referencing work on the British Library maps collections.
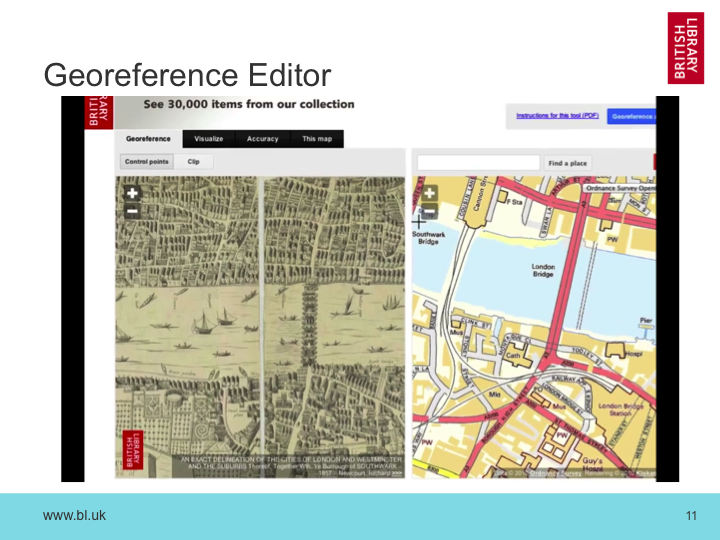
This picture shows a user helping us understand where an old digitised map lines up with a modern one. They do this by picking out specific features that appear on both, and this allow the old map to be projected on top of the new one.
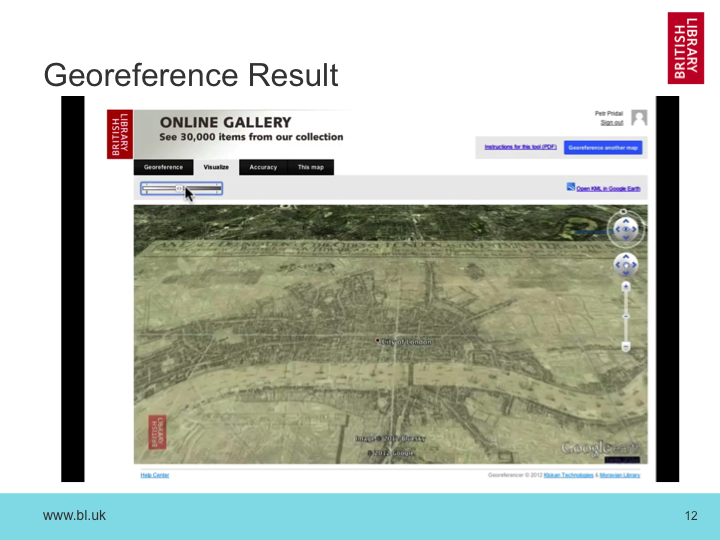
If you imagine the modern map represents the web archive, then we can overlay different sources of data if we can find common points of reference. This might be the names of publications or journals or authors, identifiers like ISBNs or DOIs, or other entities like dates or possible even place names, just like the maps. If we can find these entities and forge links with the catalogue, we can pull in more concepts from more sources and start to align the layers. As we do this, it opens up the possibility of studying the transition from print to online publication directly.
Thinking in Layers#
Now, instead of thinking in terms of chains of events, we’re thinking in terms of layers of information.
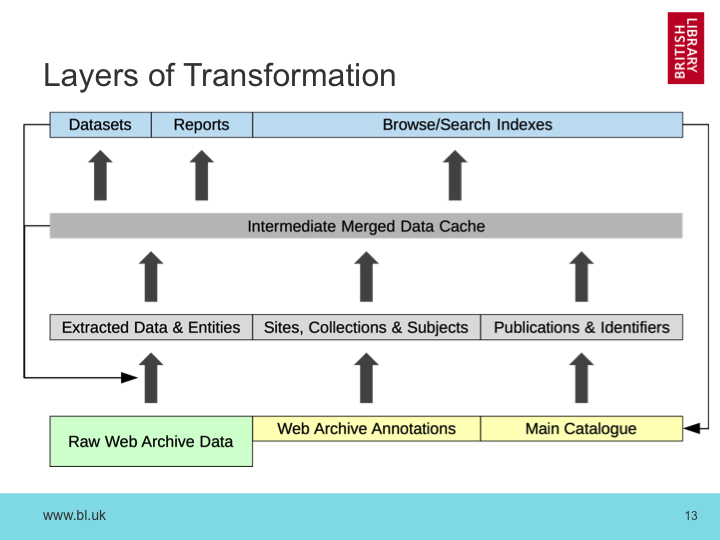
Starting at the bottom, because can’t curate or catalogue everything we use automated metadata and full-text extraction on the bulk of our the archived content. We then bring in web archive annotations that describe sites, and the collections and subject areas those sites belong to. From the main catalogue we can also start to bring in publications and their identifiers, and then all of these sources can be merged together (with the manually created metadata taking precedence). From there, we can now populate our full-text search system, or re-generate our datasets and reports.
If the outcome leads to the catalogue being updated, or if we want to add a new source of data, we can update the sources and transformations, and re-generate the whole thing all over again. Because this might mean re-processing a large amount of data, it’s probably not something we can do that often, but by taking this layered approach we can still experiment using subsets or samples of data and then re-build the whole thing when we’re confident it will work.
We can also use this approach to make the automated metadata extraction smarter - using analysis of the manual metadata to improve the extraction process. This feedback loop, with curators and cataloguers in the driving seat, will help us teach the computers to do a better job of automated extraction, so the thousands of data points we can manually curate can help make billions of resources more useful.
