
First published on the UK Web Archive blog.
Among the responses to our earlier post, How much of the UK’s HTML is valid?, Gary McGath’s HTML and fuzzy validity deserves to be highlighted, as it explores a issue very close to our hearts: how to cope when the modern web is dominated by JavaScript.
In particular, he discusses one of the central challenges of the Age Of JavaScript: making sure you have copies of all the resources that are dynamically loaded as the page is rendered. We tend to call this ‘dependency analysis’, and we consider this to be a much more pressing preservation risk than bit rot or obsolescence. If you never even know you need something, you’ll never go get it and so never even get the chance to preserve it.
The Ubiquity of <script>#
To give you an idea of the problem, the following graph shows how the usage of the <script> tag has varied over time:
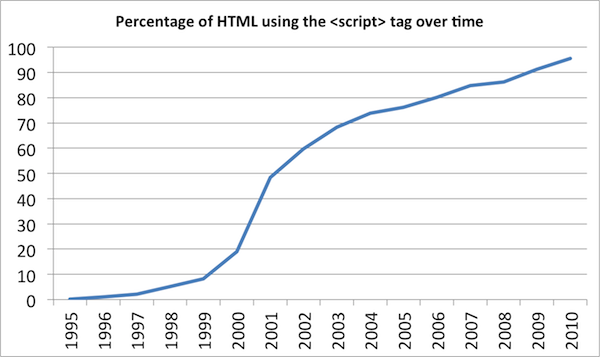
In 1995, almost no pages used the <script> tag, but fifteen years later, over 95% of web pages require JavaScript. This has been a massive sea-change in the nature of the world wide web, and web archives have had to react to it or face irrelevance.
Rendering While Crawling#
For example, for the Internet Archive’s Archive-It Service, they have developed the Umbra tool, which uses a browser testing engine based on Google Chrome to process URLs sent from the Heritrix cralwer, extract the additional URLs that content depends upon, and send them back to Heritrix to be crawled.
We use a similar system during out crawls, including domain crawls. However, rendering web pages takes time and resources, so we don’t render every single URL of the billions in each domain crawl. Instead, we render all host home-pages, and we render the ‘catalogued’ URLs that our curators have indicated are of particular interest. The architecture is similar to that used by Umbra, based around our own page rendering service.
We’ve been doing this since the first domain crawl in 2013, and so this seems to be one area where the web archives are ahead of Google and their attempts to understand web pages better.
Saving Screenshots#
Furthermore, given we are having to render the pages anyway, we have used this as an opportunity to take screenshots of the original web pages during the crawl, and to add those screenshots to the archival store (we’ll cover more of the details on that in a later blog post). This means we are in a much better position to evaluate any future preservation actions we might require to reconstruct the rendering process, and we expect these historical screenshots to be of great interest to the researchers of the future.