Web Archive Discovery Toolkit
Table of Contents
The open source tools that powered the AADDA and BUDDAH projects, and the UK Web Archive search service, is called webarchive-discovery. It can be used to analyse WARC files and build services to help search and explore web archives.
WARC and ARC indexing and discovery tools.
Analysing WARC files #
The toolkit combines an extended version of Apache Tika and WARC and ARC reading software with a number of other data and text analysis systems. Via a command line interface, or as a Hadoop task, it can parse large volumes of web archives and submit the data to a suitably configured Apache Solr, ElasticSearch or OpenSearch index.
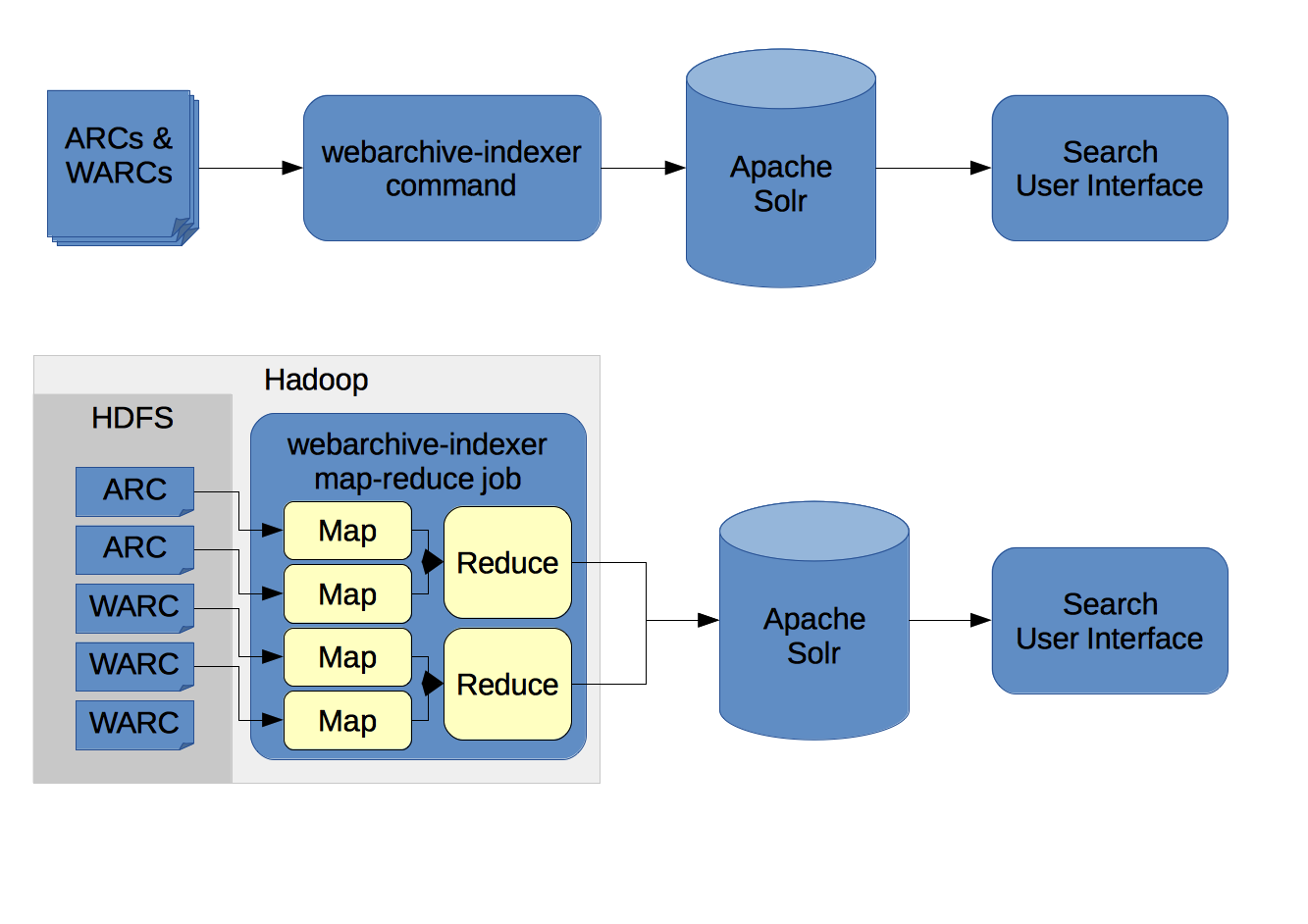
For more information, please refer to the webarchive-discovery wiki
Supporting SolrWayback #
As the system can be used to create Apache Solr or ElasticSearch/OpenSearch search indexes, those indexes can be used with any user-interface tools that support them. This includes general purpose search interfaces like Blacklight, as shown by the Warclight project.
However, to make the most of the information in the index, a more specialised user interface is needed. Our colleagues at The Royal Danish Library built just such a tool, called SolrWayback.
A search interface and wayback machine for the UKWA Solr based warc-indexer framework.
This two tools have proven to be a successful combination, and are now deployed together at various web archives across the world.
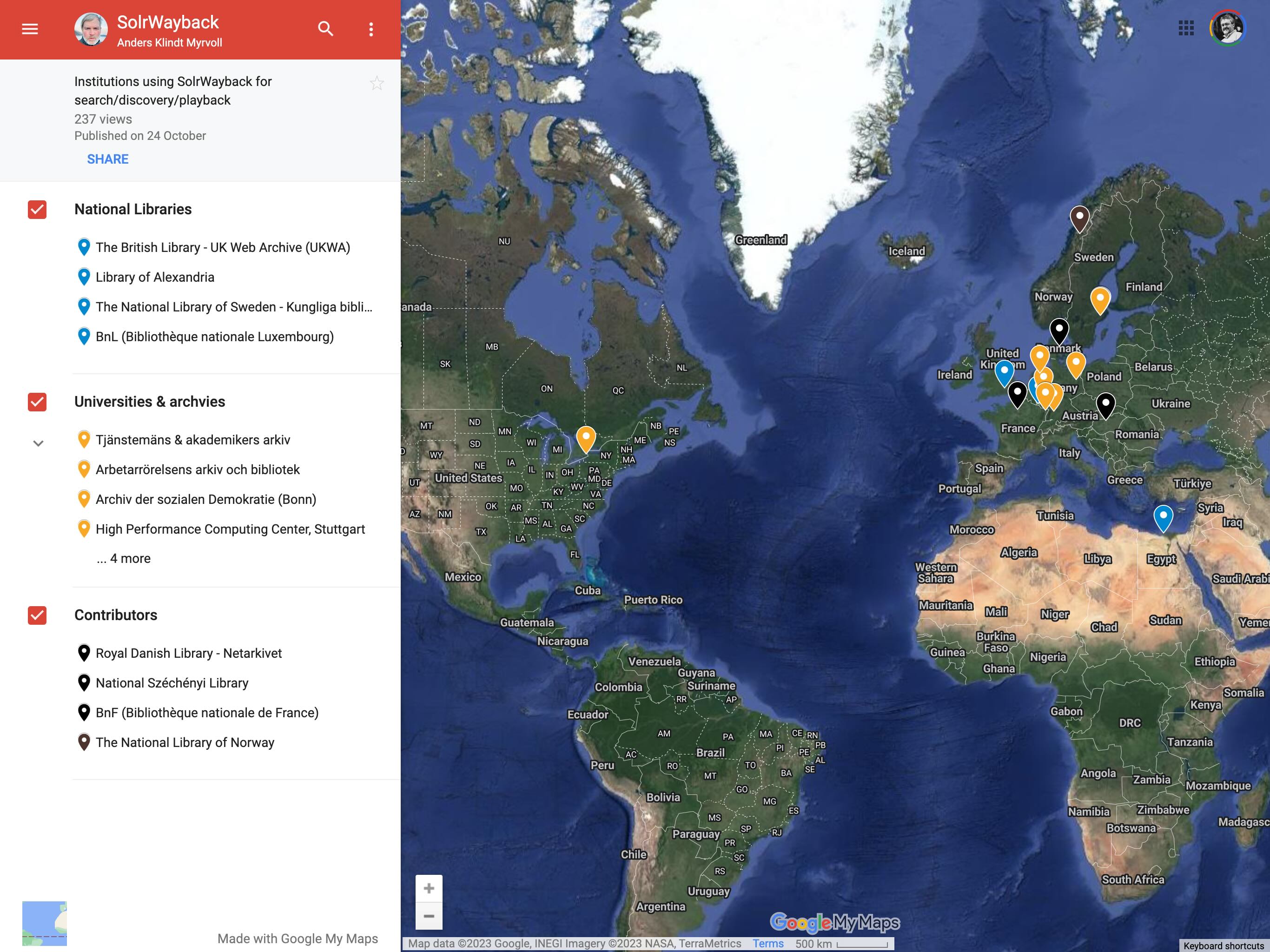
See the SolrWayback README for more information, including links to demonstration sites.