
Carefully moving files between storage systems is a critical part of digital preservation. If the number and size of the files is fairly small it’s usually a straightforward operation, perhaps using the operating system’s file browser interface to cut and paste your files.
But sometimes, something does go wrong.
Maybe there’s a power cut, or a network outage during the transfer. Maybe some kind of hardware glitch, or some other error that interrupts the copying process. Or worse: an error that happens without the copying process even noticing anything went wrong.
As the duration, size and number of transfers increases, so does the likelihood of hitting some kind of problem. At the same time, it becomes more difficult to oversee these operations, because it becomes impractical to do them by hand. This raises the risk of us failing to notice whatever errors the copying process might otherwise alert us to.
These are some of the reasons why people working in digital preservation want to perform very careful replication by comparing the source and target data files, usually using checksums like MD5 or SHA1.
Moving Web Archives#
At the UK Web Archive, to avoid our systems being too closely coupled together, our web crawlers write their output files onto dedicated storage drives rather than directly into our long-term storage cluster. Those temporary storage drives act as a buffer, and this arrangement means the crawl can keep going even if the long-term store is temporarily unavailable. But it also means we need to move the files quickly and carefully so the buffer doesn’t fill up, whcih would force the crawl to stop.
For many years, we’ve used our own in-house Python scripts to manage these transfers, carefully uploading and re-downloading data, before signing off on deleting the files from the temporary store. The general approach has been:
- The crawler downloads WARCs and logs into a Gluster volume.
- A
move-to-hdfsscript copies files from Gluster to HDFS via a HttpFS gateway. - After that, the
move-to-hdfsscript downloads them again, calculates the checksum of both copies, and deletes the original if they match.
This move-to-hdfs script only processes a single file at a time and isn’t very fast (running at about 6-7 MB/s), but nevertheless it had worked well for many years.
Until this year.
The 2023 Domain Crawl (Goes BRRRRRR)#
As mentioned in the 2023 Q1 report, this year we’ve brought the domain crawl back in-house, and given it some faster hardware so we can take advantage of the recent improvements to the British Library’s network. This has really paid off, and the crawl is really quite fast, with stable download speeds of over 1 TB/day of compressed warc.gz files.
But that’s about 12 MB/s, about twice the speed of our move-to-hdfs process. Which couldn’t keep up, so the buffer filled up in about a week, and we had to put things on hold while we decided what to do.
We could find a larger buffer, but that’s just saving up trouble for later. We needed a faster move-to-hdfs, so we had to try to work out where the performance might be improved.
The Gluster-to-HttpFS arrangement is quite complex, and relies on a mixture of physical and virtualised hardware, which makes it difficult to determine exactly where the bottlenecks are. Our initial analysis indicated that Gluster itself was part of the issue, due to the overheads of distributed data replication and contention for reading and writing to the drive. The virtual HttpFS gateway was likely also competing for network bandwidth with other services on the virtual machines.
To make the uploads faster, we decided to stop using Gluster and the HttpFS gateway, and instead use local RAID6 drives as the temporary store, and then upload directly from the crawler to HDFS. Local drives are faster, and talking directly to the Hadoop file system allows uploads to be distributed across the system from the outset. This arrangement also means the crawler is talking directly to the cluster, over dedicated physical hardware and via local network routers. This means we have much more network bandwidth available, and should see less contention with other network activity.
Refactoring our own scripts to work in this new way would certainly have been possible, but would have been quite a lot of effort. However, we’ve been looking out for alternative approaches for a while, and it looked like it was time for a change of tools.
Other Tools#
Wherever possible, we try to use high-quality and popular open source tools rather than rolling our own. But with move-to-hdfs we’d ended up a long way from there, largely because most file synchronisation tools don’t support Hadoop, but also because of how thorough we wanted the checks to be.
For example, rsync is a widely used UNIX tool for careful copying, and exactly the kind of tool we’d rather use. But it can’t talk to Hadoop directly, and it doesn’t check the files as carefully as a digital preservation audience might expect. As this StackExchange answer puts it:
This verifies that the data received are the same as the data sent with high probability, without the heavy overhead of a byte-level comparison over the network… … rsync does not reread the data and compare against the known checksum as an additional check.
There is a --checksum flag but as the documentation make clear, this is a pre-transfer check to see which files need to be updated, not a post-transfer check that the data was written correctly. To make rsync work like you might expect, you actually need to run it at least twice, adding the --checksum after the initial transfer and repeating the process until no differences are observed.
This is better than some very widely used Microsoft tools, xcopy (which seems to optionally /v validate the data as it is written to disk, but does not re-read it, and offers no equivalent of --checksum) and robocopy (which doesn’t validate the transfer at all, and relies entirely on metadata like size).
There are other tools for this kind of work which I encourage you to consider (for example, I’ve heard good things about the GUI tool FastCopy), but there was one in particular that caught my eye…
Enter Rclone#
The homepage of Rclone really speaks to my heart…
Rclone really looks after your data. It preserves timestamps and verifies checksums at all times.
Not only that, but it supports a wide range of different storage back-ends, including the Hadoop Distributed File System! And it has a rich set of command-line options to tune things like file selection, or how many threads to use. It sounded too good to be true!
Alas, so it was. To reflect reality, the front page should read something like…
Rclone really looks after your data. It preserves timestamps and verifies checksums wherever possible, depending on the kind of storage you’re using.
Don’t get me wrong, it’s still the best tool I’ve found by some margin! But there are some limitations to be aware of when using it.
Checksum Support#
Rclone supports a --checksum check when copying files, although like rsync the primary use case is checking which files have changed (this discussion thread makes clear). Nevertheless, this is a useful starting point.
But the first devilish detail is that, while local-file-to-local-file copies are checksummed using MD5 and SHA1, not all storage providers support either of those hashes (and some don’t support any kind of hash at all). This includes HDFS, which does compute normal hashes, but uses block size-dependent hashes-of-hashes (because these checksum calculations can be distributed across the cluster).
This mismatch shows up as a warning when using Rclone. For example, when trying to copy to HDFS and use a checksum:
rclone copy -vv --checksum testdata h3:/user/root/testdata
Where the h3: part is a reference to what Rclone calls a ‘remote’, which is the specific configuration of the type of storage and how to connect to it (e.g. HDFS). Having run this command, the resulting logs contain:
2023/04/28 08:19:17 NOTICE: hdfs://hadoop:9000: --checksum is in use but the source and destination have no hashes in common; falling back to --size-only
i.e. you are warned that no checksums were checked, and only the size was used to indicate whether the files were identical. It’s worth noting that this seems to be slightly worse than the mode without --checksum:
rclone copy -vv testdata h3:/user/root/testdata
..where the logs say…
2023/04/28 16:16:53 DEBUG : test.bin: Size and modification time the same (differ by -87.620005ms, within tolerance 1s)
2023/04/28 16:16:53 DEBUG : test.bin: Unchanged skipping
This indicates that both the modification times and the sizes have been used to determine what needs to be updated, whereas --checksum mode falls back on size only.
Stored Checksums#
The second devilish detail is that even where the provider does support an MD5 or SHA1 hash, it is generally not calculated by reading the data after it was written, but (like rsync) it is a record of the data that was transferred. How strong a guarantee this represents depends on the details of the storage service: e.g. the supplied checksum may (or may not) have been used to verify what was received and/or written. You have to check the Rclone documentation for the storage implementation in order to determine exactly what it’s doing.
However, Rclone does provide support for explicitly running a full check via the rclone check operation, combined with the --download option:
rclone check -vv --download testdata h3:/user/root/testdata
This doesn’t rely on whatever hashes are supported by the storage service, and instead fully downloads the files from the remote store to calculate the hash and compare them with the local copy.
This means we can first run an rclone copy and then run an rclone check , and assuming no errors are thrown by the check, then run an rclone move for the same files, which will compare the files and deleted the local copies.
rclone copy /data h3:/data
rclone check --download /data h3:/data
rclone move /data h3:/data
The downside of this approach is while the final move step doesn’t involve any checksum-based checks. The final deletion of the original files is based only on their size and timestamp.
Hashing & Caching#
Fortunately, Rclone has one additional feature that can help, the ‘hasher’ storage wrapper. This can be used to ‘wrap’ any storage backend supported by Rclone, and will record and cache the checksums of any files that pass through it. Using this, we can declare a special ‘virtual’ storage service called h3-hasher that proxy calls to the h3 store, and will remember the checksums of any files it sees.
It’s important to note that the h3-hasher will remember the checksums of the files as they are written to storage, or as they are read from storage. So, to make sure we have the checksums we want, we only want to use the h3-hasher when we do the download and check part:
rclone copy /data h3:/data
rclone check --download§ /data h3-hasher:/data
rclone move --checksum /data h3-hasher:/data
This will calculate the checksum of each file as it is downloaded during the checking process, and then remember the result locally, so it can be used for the final comparison. This ensures we would notice the (admittedly small) possibility that the local files are changed between the check and the final move, but does not rule that out for the remote storage service. However, given the way the h3 service is built and it used, this is a reasonable assumption.
The Final Recipe#
The copy/hash+cache/move procedure gets us most of the way there, but there’s a few more options to consider.
As is often the case with digital archives and repositories, we are taking small number of files and merging them to a much larger storage system, after which we do not expect the files to be change. We can improve our performance and robustness further by using Rclone options that match these assumptions:
rclone copy --no-traverse --immutable /data h3:/data
rclone check --download --one-way --no-traverse --immutable /data h3-hasher:/data
rclone move --checksum --no-traverse --immutable /data h3-hasher:/data
The --no-traverse option prevents the Rclone copy from scanning the contents of the h3 store before copying the files. There can be a lot of these files, which makes this scan slow enough that the whole copying process is significantly slower than it needs to be. In our case, this pre-copy scan is not necessary, so we skip it.
Similarly, the --one-way flag to the check command stops Rclone from looking on the cluster for files that are not held locally. The default behaviour makes sense when comparing two copies of the same files, which is the primary use case for check, but this one-way comparison is what we need, as we don’t want the check to throw an error because there are more files on the long-term store.
Finally, the --immutable flag indicates that the files on h3 are not expected to ever change once written. Therefore, if Rclone notices that there are local files that exist on Hadoop, but they differ in size/timestamp/checksum to the local files, it throws an error rather than silently updating and overwriting the file. It is unlikely that this would happen, but we still want to ensure that any such change would be noticed, and require manual attention to resolve.
An alternative to --immutable would have been to use the --backup-dir and --suffix options to ensure any files that would have been deleted or overwritten are still kept. This can be very useful in many situations, but in the case of WARC transfers we decided it would be better to force these issues to be resolved early on the temporary store. Manually managing large numbers of files in Hadoop is fairly awkward, and we’d rather be running risky operations like file deletions on local files rather than on the cluster, to limit the potential harms of accidentally typing the wrong command.
Catching Errors#
While experimenting with options, it’s fine to use simple scripts and toy environments. But on the road to production, we need to take a few more things into account. I know when an experiment fails, because I’m watching closely. But our automated systems need to run reliably without me around.
In this regard, there is a downside to relying on running three separate commands. For example, the simplest approach would be to use a bash script, like this:
#!/bin/bash
rclone copy --no-traverse --immutable /data h3:/data
rclone check --download --one-way --no-traverse --immutable /data h3-hasher:/data
rclone move --checksum --no-traverse --immutable /data h3-hasher:/data
However, if the first or second command hits an error, the defaults of how Bash works mean the script will keep running subsequent commands even if the earlier ones fail. It’s difficult to predict what the outcome will be in that case, so it makes sense to use ‘unofficial bash strict mode’
#!/bin/bash
# 'strict mode':
set -euo pipefail
rclone copy --no-traverse --immutable /data h3:/data
rclone check --download --one-way --no-traverse --immutable /data h3-hasher:/data
rclone move --checksum --no-traverse --immutable /data h3-hasher:/data
Specifically, the set -e ensures the script exits when one of the commands exit. This stops things as early as possible and allows you to work out what’s gone wrong.
However, as we are already using Apache Airflow for automation, our final implementation runs each Rclone command as a separate step in a Airflow workflow. This means we can rely on Airflow to catch errors and retry each step as appropriate.
Atomic Movements#
It’s worth pointing out one additional issue that needs to be kept in mind when integrating with a wider workflow. To ensure every step is reliable, it is very important to avoid having multiple processes operating on the same file at the same time.
For example, while writing the WARC files, the Heritrix crawler uses a version of the filename with a .open at the end. These .open files keep growing while the crawl proceeds, until they reach around 1GB (or after a time-out, if the crawl slows down). At this point, the crawler renames the file, turning example.warc.gz.open into example.warc.gz. This operation is ‘atomic’, meaning that from the point of view of the software running on that computer, this operation is instantaneous, and it is impossible to ‘see’ the file before it is in-place and complete under it’s new name.
This means we can make sure we only every try to move files that are finished, and leave any in-progress files alone, by adding Rclone options that filter out the .open files. The crawler does something similar with the crawl log files, with crawl.log being used as the in-progress name, but then renamed when a checkpoint is reached or of the crawl is restarted. The corresponding Rclone flags look lilke:
--include "*.warc.gz" --include "crawl.log.cp*" --include "crawl.log.\d+"
Rclone has great support for filtering files based on things likes names and last-modified dates, so I’d encourage you to explore them, to see what suites your use case.
Rclone Atomicity#
Just as Heritrix has to be careful about how it writes files so tools llike Rclone can do their work, any downstream processing also needs to take into account how Rclone writes its files, as this is dependent on the storage back end you are using.
For example, when writing files to local storage Rclone only recently added support for using temporary filenames during downloads (as of 2023-05-08 in v1.63.0). In earlier versions, it would be necessary to wait until the Rclone operation completed without errors.
In other cases, Rclone does not need to do anything special because the storage system itself ensures certain operations are atomic. Fortunately, Hadoop automatically using a temporary name during uploads, thus guaranteeing that and downstream workflows do not see half-written files. This means we can avoid having those downstream processes coupled to the upload operations (e.g. awaiting some signal that those writes are complete). Instead, we can run independent workflows, making the whole system easier to manage.
Production Performance#
So great, it’s up and running, but the question is, is it fast enough? Did all this re-engineering pay off?
In short: Yes.
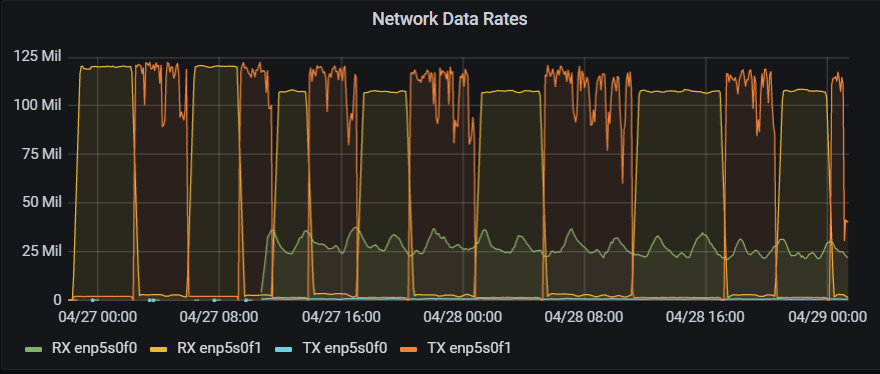
This graph shows the alternating downloads (yellow) and uploads (orange), saturating at 125MB/s. This corresponds to the maximum possible throughput of the 1Gbps connection the crawler has to use to communicate with the Hadoop cluster.
But this does show another side-effect of having to run separate upload and download steps. i.e. because read and write are seqential, this connection allows a theoretical maximum of ~63MB/s overall. The observed rate is about 56MB/s, which is pretty good given there are always some overheads with these types of network connection, and certainly much faster than the 6-7MB/s of the original approach.
Ideal Options#
We spent a little time looking at tuning the level of parallelism via the --checkers X and --transfers X options, but looking at the network metrics, it quickly became clear that the defaults (8 and 4 respectively) were good enough. What would have made a difference would have been having some way to run the read and the writes at the same time.
Our 1GB/s connection is a full duplex connection, meaning outgoing and ingoing transfers can both run at up to 1GB/s simultaneously. But as things are, our Rclone workflow cannot take advantage of this.
Ideally, we would like a --download option to the copy and move commands, as proposed here. This would work just like the check --download option, forcing a download after the upload and calculating the checksum on that basis. It would also allow us to reduce the whole operation to a single rclone move command, which would further simplify things.
Unfortunately, while we have contributed some code to RClone, the changes required here are too difficult for us to implement without assistance. If anyone can make use of the prototype code in that discussion, or has any ideas about how to support improvements to Rclone, I’d be very happy to hear from you!