
First publicised in this UK Web Archive blog post.
This is a summary of what’s been going on since the 2022 Q4 report.
Summarising Our Holdings#
We regularly report on our holdings so other teams across the Legal Deposit Libraries have an understanding of how much data we hold and how we grow over time. Until recently, the reporting mechanism we used did not fully take into account the storage used across different clusters, and on Amazon Web Services.
In January the old reporting mechanism was replaced with a new implementation, better integrated with our other systems and covering all storage services. The Airflow scheduler (discussed in previous reports) generates updated lists of holdings from different systems, and a Jupyter notebook is then used as a dashboard. This is made accessible via the W3ACT curation service, unlike the old system, which was only available to British Library staff.
While it doesn’t get updated automatically, there’s also an older copy of the notebook on GitHub. See UK Web Archive Holdings Summary Report. As you can see there, the UK Web Archive now holds over 1.4 PB of WARCs and logs.
Legal Deposit Access Solution#
The new system for Reading Room access to Non-Print Legal Deposit material has also made steady progress. An alpha version of the system has been rolled out across all LDLs so staff can access the service for testing, and a beta service is being rolled out to run alongside the current system in reading rooms. The deployment of the services themselves has also been automated, using GitLab CI/CD to updated the systems rather than relying on updating them by hand.
Staff testing raised some additional requirements to be met before the service roll-out can proceed. Working with Webrecorder to meet these requirements will be the focus for the next quarter.
UKWA Website#
Edited 28th April 2023 to include translation updates.
The main website has been updated to run version 2.6.9 of our PyWB playback engine, and version 1.4.5 of the main search interface. Version 1.4.5 does not change the sites basic functionality, but does significantly improve the Scotting Gaelic version of the site.
However, we’ve also looked at more significant changes to the public interface to the archive.
Firstly, we’d like to update to newer version of PyWB, which now features an updated timeline and calendar display. Secondly, some experimentation with letting search engines to index selected website showed that it may be necessary to include links to the archived sites somewhere in the main site so that the crawler finds and prioritizes those URLs for indexing. To test this out, a page has been added to the site that lists any archived sites that require indexing, and that page has been included in the site map.
Finally, we’ve found a lot of queries are better answered by direct URL search than keyword search, so wanted to find ways to better integrate PyWB’s URL search functionality with the main site. To make URL search easier to use, we want to change the the main search interface on the front page of the website to spot URL searches and direct the user to the right results.
The BETA version of the website has been updated to include these changes, and is now available For review. If you have any feedback, please let us know.

Web Archive Discovery tool updates#
One long-standing issue we have is that our full-text search does not contain recent material, and over the next year we hope to revisit the scaling problems we’ve seen and try to improve the situation.
As an initial step towards this, we spent some time updating our search tools. The webarchive-discovery indexer has been updated to use version 2 of Apache Tika, along with other upgrades to other dependencies like the Nanite wrapper that makes is possible for us to use National Archive’s PRONOM/DROID format identification engine. This changes are quite significant, so the version number has been bumped from 3.3.x to 3.4.x.
We are also considering an alternative workflow, where we store the extracted metadata in an intermediate form, rather than going directly to Apache Solr or Elasticsearch. To enable us to experiment with this approach, the indexer has been modified to support writing the extracted metadata to JSON Lines output files so that we can use it to support multiple forms of indexing or analysis.
2023 Domain Crawl Preparation#
As discussed in the previous report, this year we are bringing the domain crawl back on-site rather than running on the cloud. The technical preperation for this was fairly straightforward, given the deployment of the crawl is largely automated. The main change from the last on-site crawl is that we switched to using a server with plenty of fast SSD disks. The cloud crawls had shown us how much the whole thing can benefit from faster disks, so we have attempted to match that when running on our own servers.
Add some updated seed lists from Nominet and from our curators, and we are ready to roll on the anniversary of the first Non-Print Legal Deposit domain crawl. That one started on the 12th of April 2013, and so we’ve chosen that for our start date this year. This will be part of the wider celebrations from across the legal deposit libraries.
Addendum - 13th April 2023#
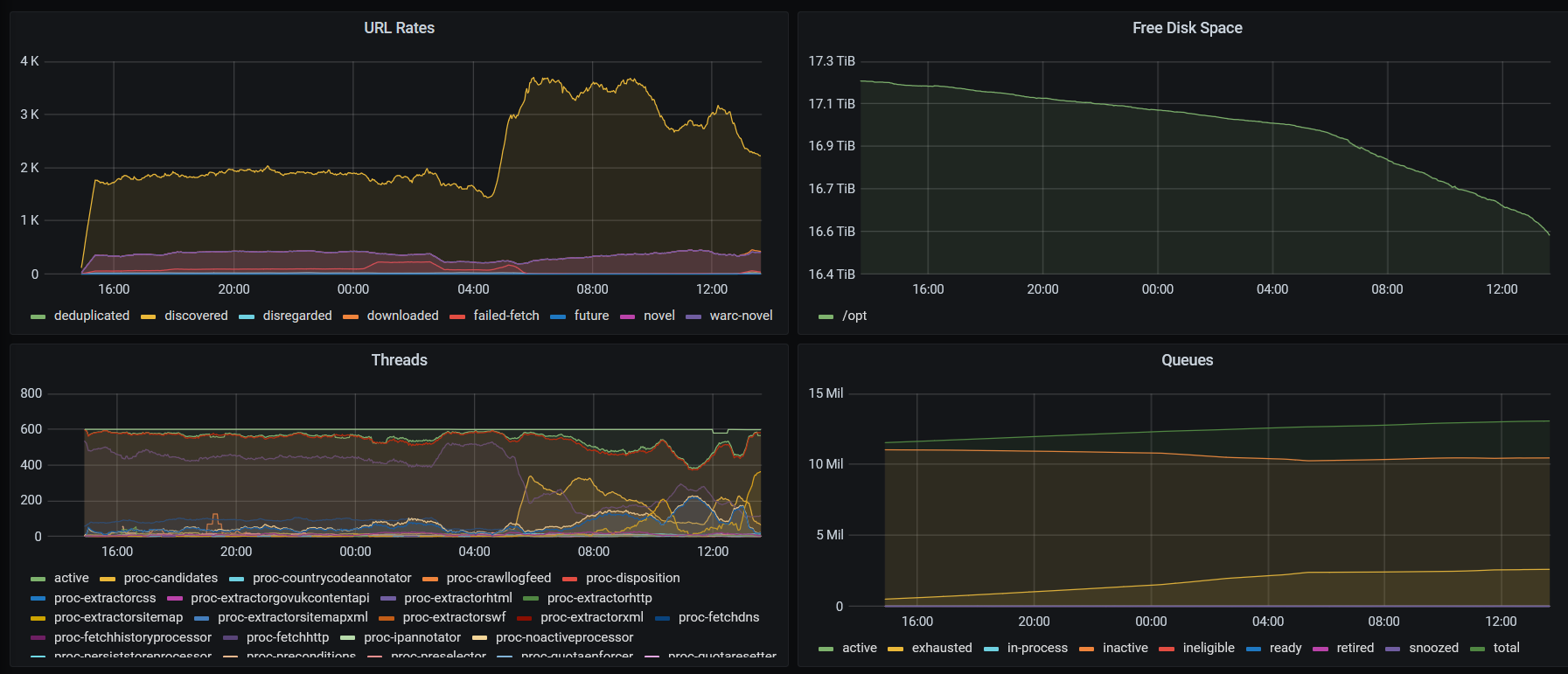
Due to staff holidays, we are only now publishing this quarterly report, so we can add some notes on the launch of the 2023 domain crawl.
The crawl was set up on the 11th, and loaded with the 11 million seed URLs from Nominet and the 27,059 domain crawl seeds from W3ACT (including 13,460 non-UK seeds). On the morning of the 12th, the crawl was launched, and seems to be running well, at around 400 URLs per second. If the system can sustain this rate, which corresponds to around one billion URLs per month, the whole crawl should complete in 2-3 months time.
For more information on the anniversary of Non-Print Legal Deposit, see Celebrating ten years of collecting the UK Web Space.