
This is a summary of what’s been going on since the update at the start of the autumn.
- TOC {:toc}
2022 Domain Crawl Completion#
As in previous years, the 2022 Domain Crawl continued to run right up until the end of the year. Overall, things ran smoothly, with only brief outages for upgrading the virtual server over time as the size of the frontier grew.
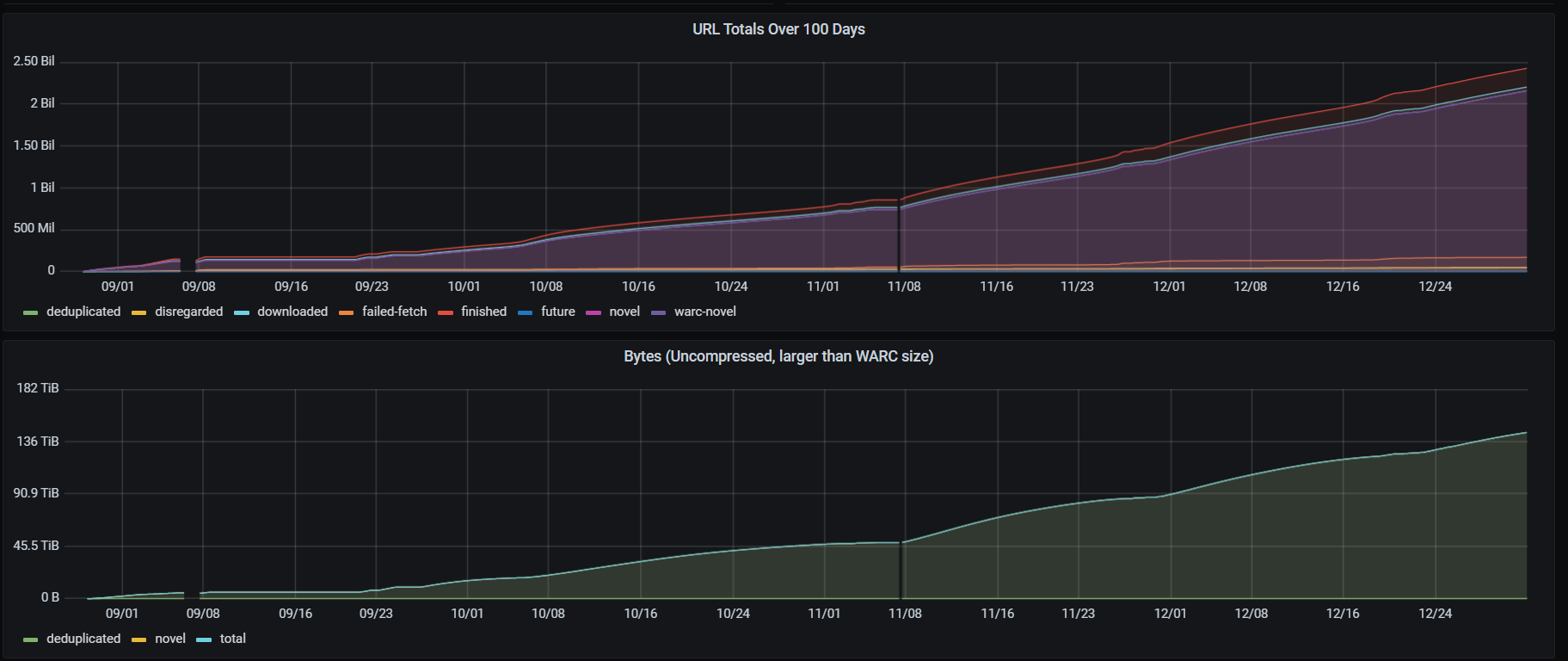
Because we’re running on the cloud, we are paying for how much compute capacity, RAM and disk space we’re using. So, when the crawl is young and the Heritrix3 frontier database is small, it makes sense to use a small computer. But as the crawl frontier grows, so does the amount of RAM the crawler needs to manage the frontier, so we scale up as we go.
This is one of the reasons we spent time making it possible to configure the frontier database so more house-keeping and clean-up processes are run while the crawl is running. This helps Heritrix clear disk space after it has dealt with URLs, and led to significant savings. The 2020 crawl ended up using 45TB of disk space to store the crawl state, and deleting old ‘checkpoint’ files (which can be used to revert the crawl state to a previous point in time) did not help free up more space. But after changing those configuration options, the 2021 and 2022 crawls only needed 15TB of space, and deleting checkpoints was much more effective.
2023 Domain Crawl Planning#
We originally moved to the cloud to relieve pressure on the BL networks as staff switched to remote working during the pandemic. But even when COVID restrictions were eased, the library has continued to support staff working remotely where possible. Fortunately, over the last year the library has upgraded many of the network systems across both the London and Boston Spa sites, which means we now have permission to run the 2023 crawl on site.
As there is still some uncertainty as to how this will affect other network users, we are planning to begin the crawl much earlier in the year (perhaps as early as February). This gives us more time to revisit our options if something goes awry.
Internal Collections API#
Working with the Archives of Tomorrow project to understand their requirements, we now have an internal API where W3ACT metadata can be downloaded for entire collections, including all sub-collections and target site metadata. Authenticated W3ACT users can retrieve these full collection extracts (including unpublished collections), which are updated daily. The JSON files are available at https://www.webarchive.org.uk/act/static/api-json-including-unpublished/collection/ for logged-in users.
The public version of the API is in the final stages of development, and should be released early in 2023. Unlike the internal API, this will not include collections that are not yet ready for publication.
W3ACT 2.3.4#
Just a few days ago, W3ACT 2.3.4 was released. This included a number of tweaks and bugfixes, including correcting the CSV export feature and adding more export formats (TSV and JSON). For more details, please take a look at the associated release milestone.
There was also an issue with how W3ACT data was used, meaning the subdomains of sites with open access licences were being given the same licence as the ‘parent’ domain. This has now been resolved and access is consistent with the data in W3ACT.
Document Harvester Outage#
From the 12th of December onwards, the Document Harvester had stopped picking up GOV.UK documents properly. This appears to have stemmed from some edits carried out in W3ACT, where the Watched Target that covered the GOV.UK document publication service was merged with the main GOV.UK Target (which was not Watched). This meant the crawler was no longer looking for documents from GOV.UK.
We made the GOV.UK Target into a Watched Target, and then cleared the relevant crawl logs for re-processing. Those logs have now been processed and the missed documents have been identified.
We’re looking at how this happened and will take steps to prevent this happening in the future.
Legal Deposit Access Solution#
The Application Support team has been working with Networks team and our Legal Deposit Library partners to start to roll out an initial ‘alpha’ service across all sites. This will help all library staff to try out the system and lay the foundations for a ‘beta’ service in reading rooms. The Project Manager has also been working hard to understand the likely timeline for the project and communicate this to all stakeholders, while keeping the project management triangle in mind.
Additionally, we’re working on setting up a suitable Continuous Deployment pipeline for this service using GitLab CI/CD. This will allow us to analyse, test and safely deploy new versions of the access service without having to manage the system by hand.
CDX Backfill#
One of the critical components of the web archive is the content index (CDX), which is an index of all the URLs we have archived, and is required for playback to work. Ours runs on OutbackCDX (from the National Library of Australia), and a subset of it’s functionality is available via our API.
In the past, we’ve had problems running large CDX indexing jobs, and this had left us in an unfortunate situation where the 2016, 2018 and 2019 domain crawls were not indexed. During the last few months, we modified the the indexing process to (re)process our WARCs and ‘backfill’ the index, which has filled in those gaps.
This also showed that we could process our entire collection (i.e. over 1PB) in a reasonable time (roughly three months depending on the precise workload), which is reassuring. It will likely be necessary to re-build indexes from time to time, and it’s good to know it should be possible to do so in a reasonable amount of time. Also, the act of reading every byte of every WARC is an additional explicit proof that the files have been kept safe over all these years! We know HDFS has been systematically monitoring the files over time, but it’s nice to run an independent check.
The 2020, 2021 and 2022 domain crawls will have to wait a little longer, as they are stored on Amazon Web Services and need transferring to the British Library before they can be indexed.
Browsertrix-Cloud#
Finally, we’re proud to be part of the IIPC project Browser-based Crawling For All, which contributes to the development of Browsertrix Cloud and attempts to ensure IIPC members can take advantage of it. As part of this, we proposed two sessions for next years’ IIPC conference, both of which have been accepted:
- A workshop called Browser-Based Crawling For All: Getting Started with Browsertrix Cloud, aimed at helping attendees take advantage of Browsertrix Cloud. We’re particularly interested in uncovering barriers that might prevent adoption.
- A panel called Browser-Based Crawling For All: The Story So Far, giving an insight into the current state of the project and of Browsertrix Cloud (including any feedback from the workshop).
Hoping to see you there!