Abstract#
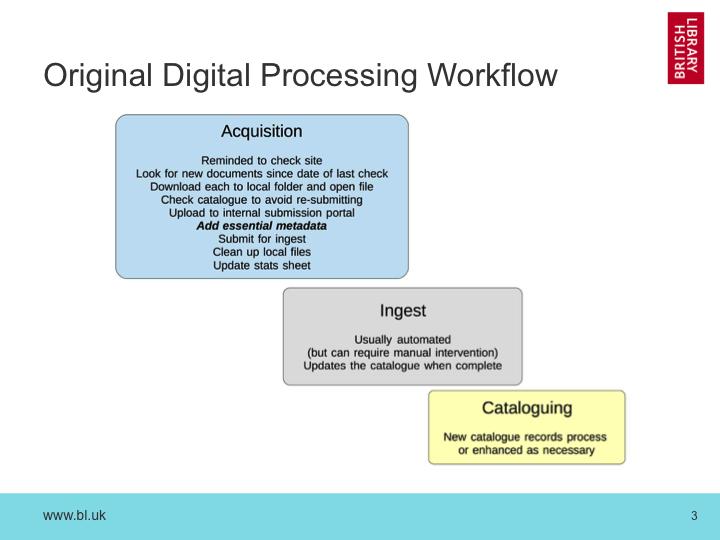
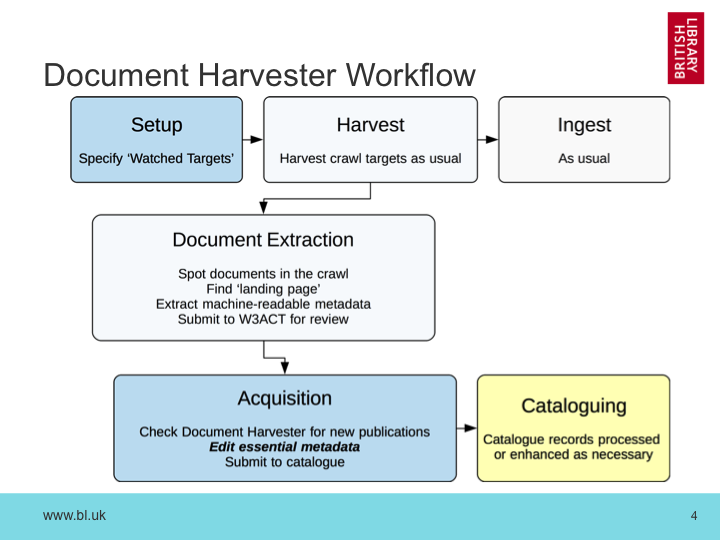
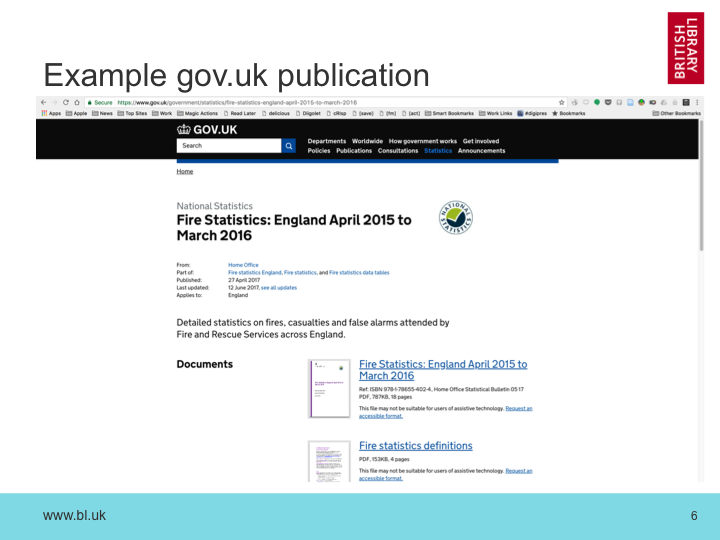
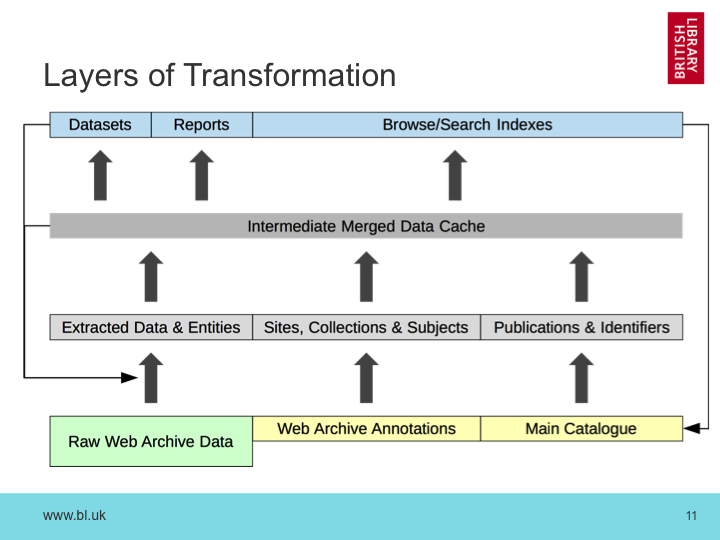
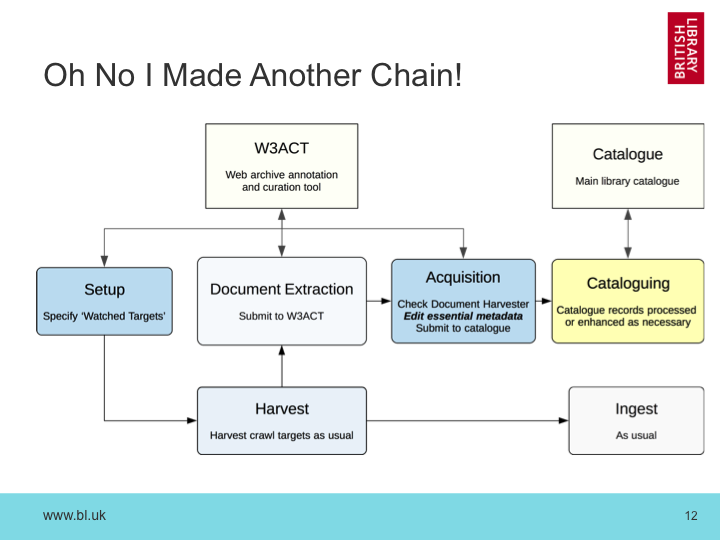
As an increasing number of government and other publications move towards online-only publication, we are force to move our traditional Legal Deposit processes based on cataloging printed media. As we are already tasked with archiving UK web publications, the question is not so much ‘how to we collect these documents?’ rather ‘how to we find the documents we’ve already collected?’. This presentation will explore the issues we’ve uncovered as we’ve sought to integrate our web archives with our traditional document cataloging processes, especially around official publications and e-journals. Our current Document Harvester will be described, and it’s avantages and limitations explored. Our current methods for exploiting machine-generated metadata will be discussed, and an outline of our future plans for this type of work will be presented.
These are the slides for the presentation I gave as part of Web Archiving Week 2017, on Thursday 15th of June.