
As published on the UK Web Archive blog.
Over the last year, we have been a part of the Big UK Domain Data for the Arts and Humanities project, with the ambitious goal of building a ‘historical search engine’ covering the early history of the UK web. This continues the work of the Analytical Access to the Domain Dark Archive project but at a greater scale, and moreover, with a much more challenging range of use cases.
We presented the current prototype at the International Digital Curation Conference last week (written up by the DCC here), and received largely positive feedback, at least in terms of how we have so far handled the scale of the collection (although the impromptu load-test that followed our presentation showed that supporting many users at once is still a challenge!).
Evaluating our ‘historical search engine’#
However, we are eagerly awaiting the results of the real test of this system, from the project bursary holders. Ten researchers have been funded as ’expert users’ of the system, each with a genuine historical research question in mind. Their feedback will be critical in helping us understand the successes and failures of the system, and how it might be improved.
One of those bursary holders, Gareth Millward, has already talked about their experiences, including this (somewhat mis-titled but otherwise excellent) Washington Post article “I tried to use the Internet to do historical research. It was nearly impossible.” Base on that, it seems like the results are something of a mixed bag (and from our informal conversations with the other bursary holders, we suspect that Gareth’s experiences are representative of the overall outcome). But digging deeper, it seems that this situation arises not simply because of problems with the technical solution, but also because of conflicting expectations of how the search should behave.
For example, as Gareth states, if you search for RNIB using Google, the RNIB site and other information about the organisation is delivered right at the top of the results.
But does this reflect what our search engine should do?
When Google ranks its results, it is making many assumptions. Assumptions about the most important meanings of terms. Assumptions about the current needs of its users. Assumptions about the information interests of individual user that performed the search (a.k.a. the filter bubble). What assumptions should we make? Are we even playing the same game?
Relevant to whom?#
One of the most important things we have learned so far is that we are not playing the same game, and the information needs of our researchers might be very different to those of a normal search (and indeed different between different users). When a user searches for ‘iphone’, Google might guess that you care about the popular one, but perhaps a historian of technology might mean the late 1990’s Internet Phone by VocalTec. Words change their meaning over time, and we must enable our researchers to discover and distinguish the different usages. As Gareth says “what is ‘relevant’ is completely in the eye of the beholder.”
Moreover, in a very fundamental way, the historians we have worked with are not searching for the one top document, or a small set of documents about a specific topic. They look to the web archive as a refracting lens onto the society that built it, and are using these documents as intermediaries, carrying messages from the past and about the past. In this sense, caring about the first few hits makes no sense. Every result is equally important. Every data point is a voice.
Slicing & dicing#
To help understand these whole sets of results, we have endeavored to add appropriate filtering and sorting options that can be used to ‘slice and dice’ the data down into more manageable chunks. At the most basic level (and contrary to the Washington Post article), the results can be sorted, and the default is to sort by ascending harvest date. The contrast with a normal search engine is perhaps no more stark than here – where BING or Google will generally seek to bring you the most recent hits, we start in the past and look forwards (something that is very difficult to achieve using a normal search engine).
With so many search options, perhaps the biggest challenge has been to present them to our users in a comprehensible way. For example, the problem where the RNIB advertisements for a talking watch were polluting the search results can be easily remedied if you combine the right search terms. The text of the advert is highly consistent, and therefore it is possible to precisely identify those advertisements by searching for the text “in associate with the RNIB”. This means it is possible to refine a search for RNIB to make sure we exclude those results (as you can see below). But while this is possible, it’s a rather clumsy user experience.
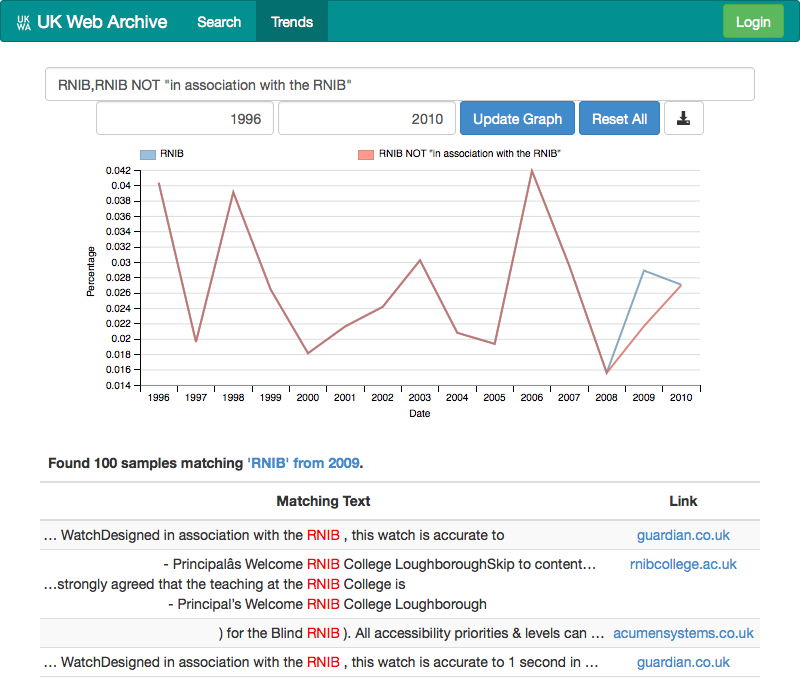
These problems are even more marked when it comes to trying to allow network analysis to be exploited. We do already extract links from the documents, and so it is already possible to show how the number of sites linking to the RNIB has changed over time, but it is not yet clear how best to expose and utilize that information. At the moment, the best solution we have found is to present this network links as additional search facets. For example, here is the results for the sites that linked to rnib.org.uk in 2000, which you can contrast with those for 2010. Again, this makes basic network analysis possible, but it does not yet feel like we have worked out how to make network analysis feel natural and provide real insight.
Refining searchers further#
Currently, we expect that refining a search on the web archive will involve a lot the kind of operations described above – combining more and more search terms and clauses to help focus in on the documents of interest. Looking further ahead, we envisage that future iterations of this kind of service might take the research queries and curatorial annotations we collect and start to try to use that information to semi-automatically classify resources and better predict user needs.
A ‘Macroscope’, not a search engine#
So, despite the fact that it helps get the overall idea across, calling this system a ‘historical search engine’ turns out to be rather misleading. The actual experience and ‘information needs’ of our researchers are very different from that case. This is why we tend to refer to this system as a Macroscope (see here for more on macroscopes), or as a Web Observatory. Sometimes a new tool needs a new term.
Throughout all of this, the most crucial part has been to find ways of working closely with our users, so we can all work together to understand what a macroscope might mean. We can build prototypes, and use our users’ feedback to guide us, but at the same time those researchers have had to learn how to approach such a complex, messy dataset. Both the questions and the answers have changed over time, and all parties have had their expectations challenged. We look forward to continuing to build a better macroscope, in partnership with that research community.