
First published on the UK Web Archive blog.
The UK Web Archive started archiving web content towards the end of 2004 (e.g. The Hutton Enquiry). If we want to look back at the (almost) ten years that have passed since then, can we find a way to see how much we’ve achieved? Are the URLs we’ve archived still available on the live web? Or are they long since gone? If those URLs are still working, is the content the same as it was? How has our archival sliver of the web changed?
Looking Back#
One option would be to go through our archives and exhaustively examine every single URL, and work out what has happened to it. However, the Open UK Web Archive contains many millions of archived resource, and even just checking their basic status would be very time-consuming, never mind performing any kind of comparison of the content of those pages.
Fortunately, to get a good idea of what has happened, we don’t need to visit every single item. Our full-text index categorizes our holdings by, among other things, the year in which the item was crawled. We can therefore use this facet of the search index to randomly sample a number of URLs from each year the archive has been in operation, and use those to build up a picture that compares those holdings to the current web.
URLs by the Thousand#
Our search system has built-in support for randomizing the order of the results, so a simple script that performs a faceted search was all that was needed to build up a list of one thousand URLs for each year. A second script was used to attempt to re-download each of those URLs, and record the outcome of that process. Those results were then aggregated into an overall table showing how many URLs fell into each different class of outcome, versus crawl date, as shown below:
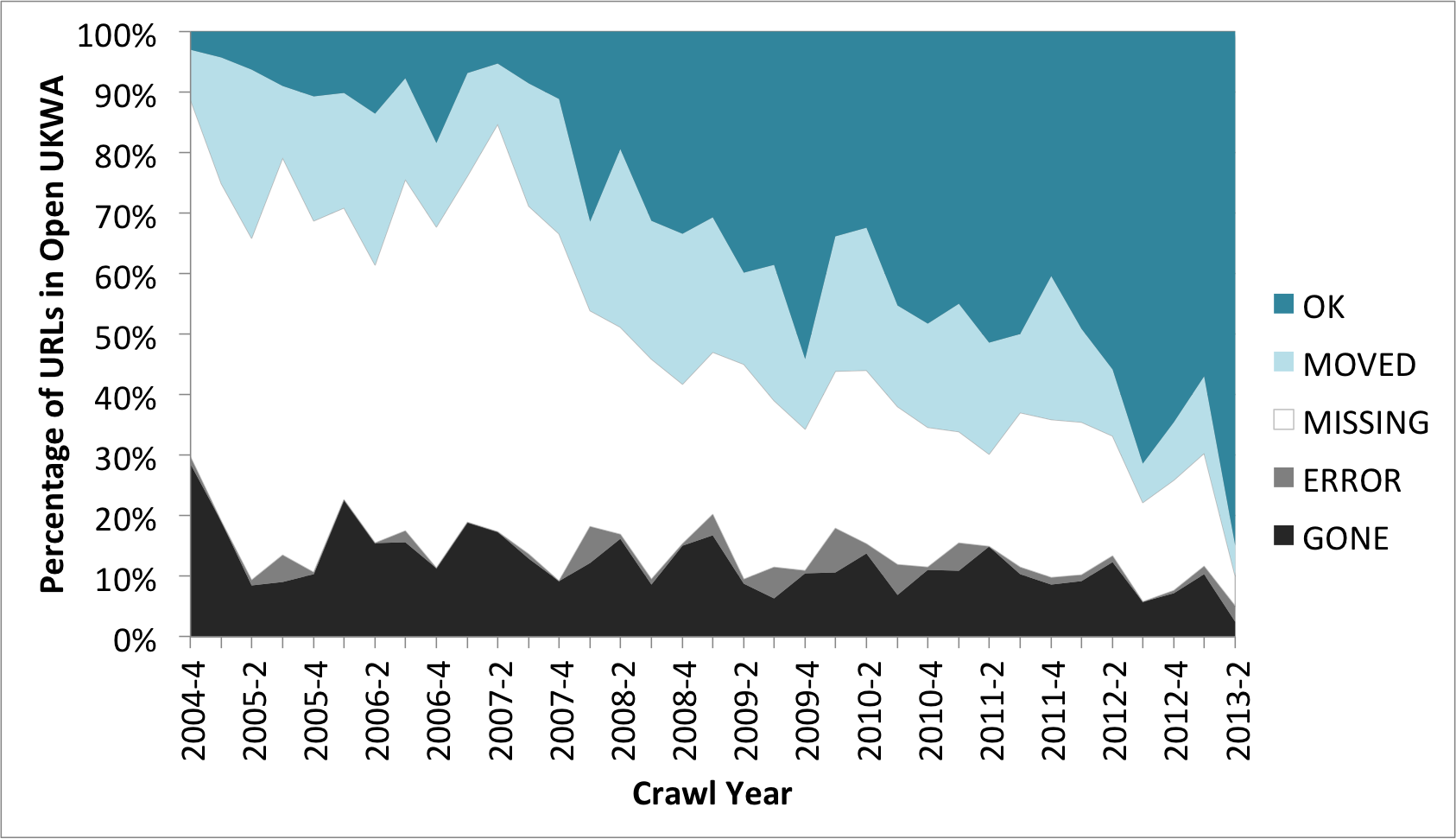
Here, ‘GONE’ means that not only is the URL missing, but the host that originally served that URL has disappeared from the web. ‘ERROR’, on the other hand, means that a server still responded to our request, but that our once-valid URL now causes the server to fail.
The next class, ‘MISSING’, ably illustrates the fate of the majority of our archived content - the server is there, and responds, but no longer recognizes that URL. Those early URLs have become 404 Not Found (either directly, or via redirects). The remaining two classes show URLs that end with a valid HTTP 200 OK response, either via redirects (‘MOVED’) or directly (‘OK’).
The horizontal axis shows the results over time, since late 2004, broken down by each quarter (i.e. 2004-4 is the fourth quarter of 2004). The overall trend clearly shows how the items we have archived have disappeared from the web, with individual URLs being forgotten as time passes. This is in contrast to the fairly stable baseline of ‘GONE’ web hosts, which reflects our policy of removing dead sites from the crawl schedules promptly.
Is OK okay?#
However, so far, this only tells us what URLs are still active - the content of those resources could have changed completely. To explore this issue, we have to dig a little deeper by downloading the content and trying to compare what’s inside.
This is very hard to do in a way that is both automated and highly accurate, simply because there are currently no reliable methods for automatically determining when two resources carry the same meaning, despite being written in different words. So, we have to settle for something that is less accurate, but that can be done automatically.
The easy case is when the content is exactly the same – we can just record that the resources are identical at the binary level. If not, we extract whatever text we can from the archived and live URLs, and compare them to see how much the text has changed. To do this, we compute a fingerprint from the text contained in each resource, and then compare those to determine how similar the resources are. This technique has been used for many years in computer forensics applications, such as helping to identify ‘bad’ software, and here we adapt the approach in order to find similar web pages.
Specifically, we generate ssdeep ‘fuzzy hash’ fingerprints, and compare them in order to determine the degree of overlap in the textual content of the items. If the algorithm is able to find any similarity at all, we record the result as ‘SIMILAR’. Otherwise, we record that the items are ‘DISSIMILAR’.
Processing all of the ‘MOVED’ or ‘OK’ results in this way leads to this graph:
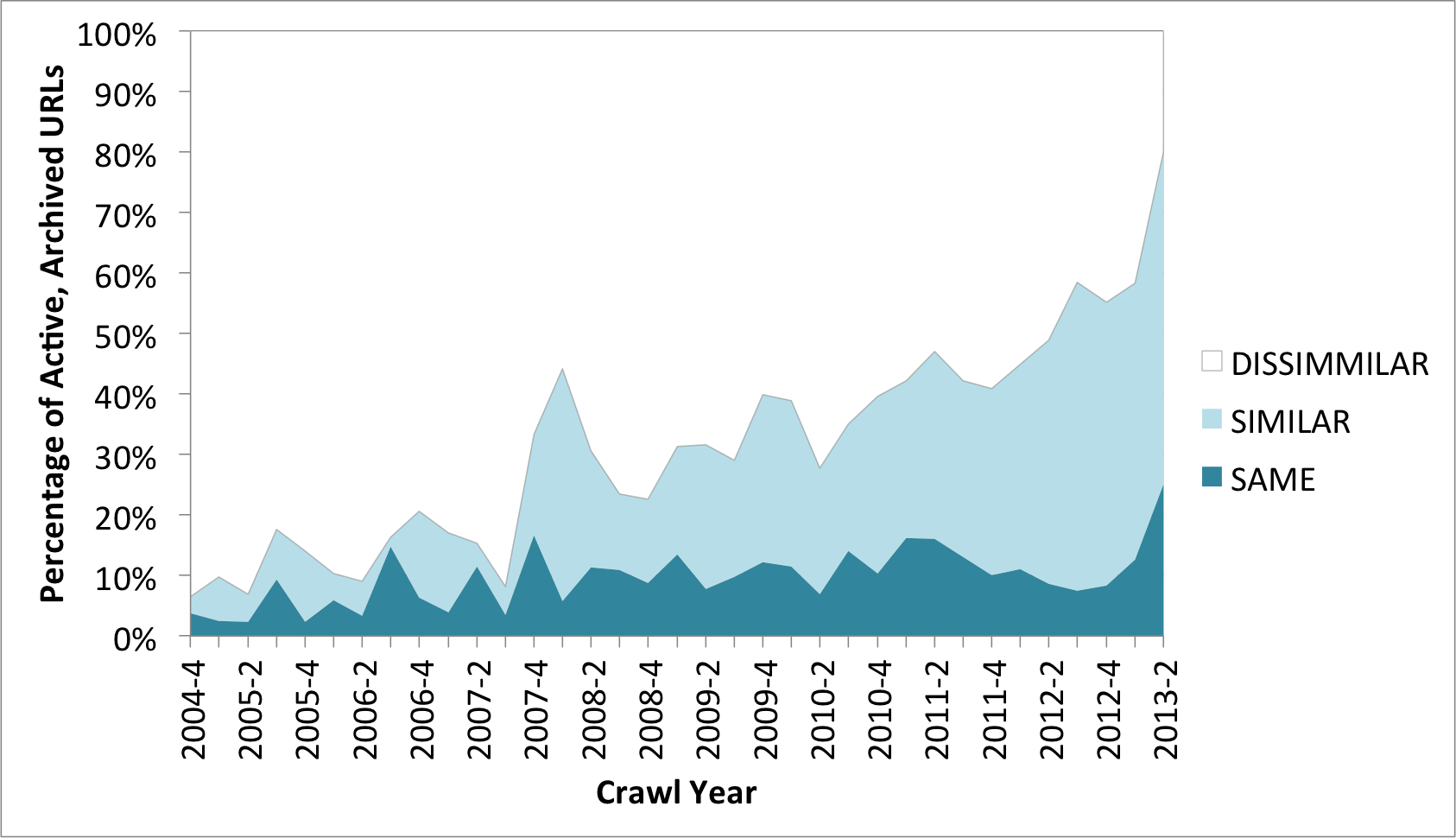
So, for all those ‘OK’ or ‘MOVED’ URLs, the vast majority appear to have changed. Very few are binary identical (‘SAME’), and while many of the others remain ‘SIMILAR’ at first, that fraction tails off as we go back in time.
Summarizing Similarity#
Combining the similarity data with the original graph, we can replace the ‘OK’ and ‘MOVED’ parts of the graph with the similarity results in order to see those trends in context:
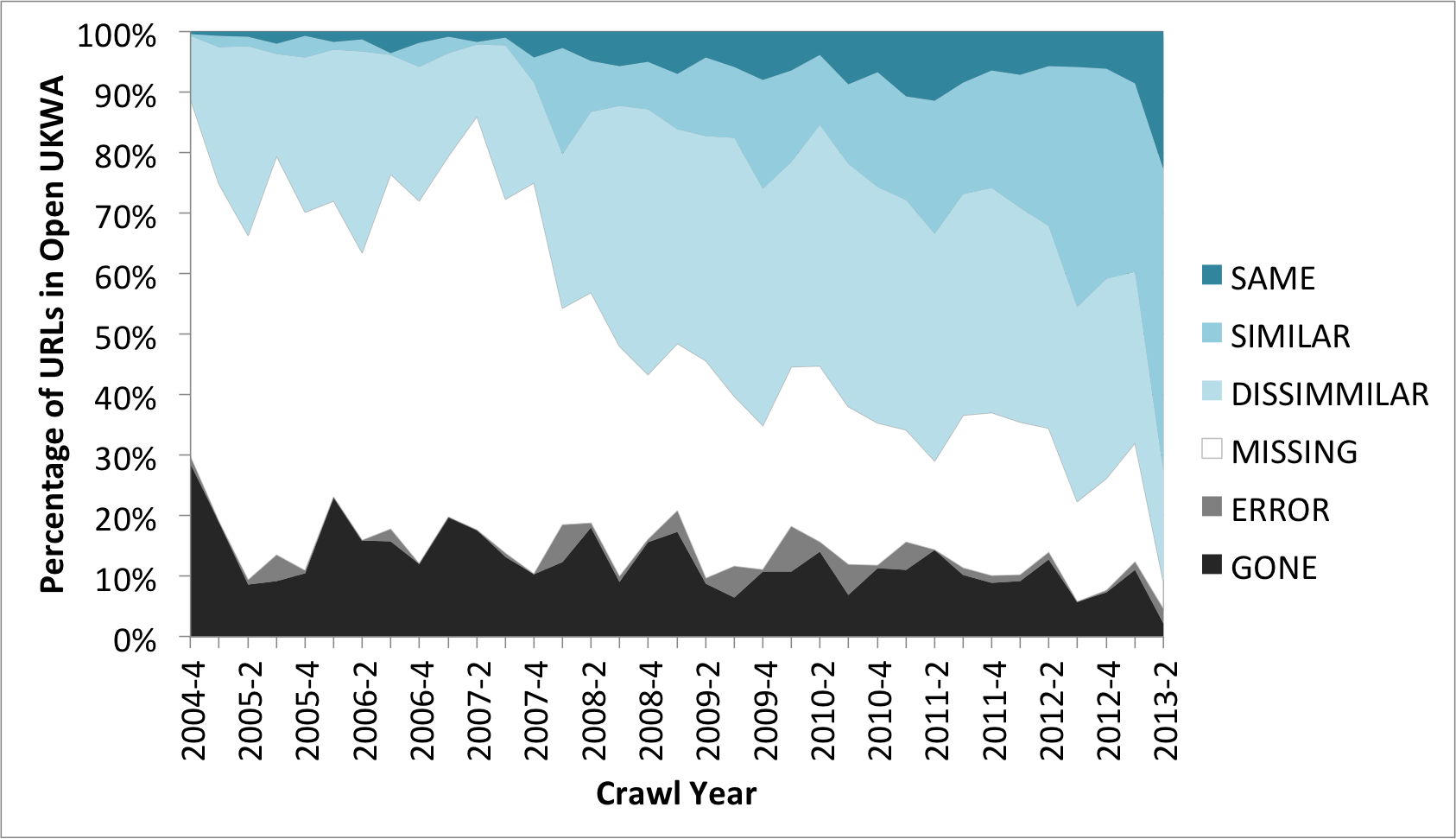
Shown in this way, it is clear that very few archived resources are still available, unchanged, on the current web. Or, in other words, very few of our archived URLs are cool.
Local Versus Global Trends#
While this analysis helps us understand the trends and value of our open archive, it’s not yet clear how much it tells us about other collections, or global trends. Historically, the UK Web Archive has focused on high-status sites and sites known to be at risk, and these selection criteria are likely to affect the overall trends. In particular, the very rapid loss of content observed here is likely due to the fact that so many of the site we archive were know to be ‘at risk’ (such as the sites lost during the 2012 NHS reforms). We can partially address this by running the same kind of analysis over our broader, domain-scale collections. However, that would still bias things towards the UK, and it would be interesting to understand how these trends might differ across countries, and globally.