- Blog/
How much of the UK's HTML is valid?

Table of Contents
First published on the UK Web Archive blog.
How much of the HTML in the UK web archive is valid HTML? Despite its apparent simplicity, this turns to be a rather difficult question to answer.
What is valid HTML anyway? #
What do we mean by valid?
Certainly, the W3C works to create appropriate web standards, and provides tools to assist validation according to those standards that we could re-use.
However, the web browser software that you are using has its own opinion as to what HTML can be. For example, during the ‘ browser wars’, competing software products invented individual features in order to gain market share while ignoring any effort to standardise them. Even now, although the relationship between browsers is much more amicable, some of the browser vendors still maintain their own ‘ living standard’ that is similar to, but distinct from, the W3C HTML specification. Even aside from the issue of which definition to validate against, there is the further complication that browsers have always attempted to resolve errors and problems with malformed documents (a.k.a. ‘ tag soup’), and do their best to present the content anyway.
Consequently, anecdotally at least, we know that a lot of the HTML on the web is perfectly acceptable despite being invalid, and so it is not quite clear what formal validation would achieve. Furthermore, the validation process itself is quite a computationally intensive procedure, and few web archives have the resources to carry out validation at scale. Based on this understanding of the costs and benefits, we do not routinely run validation processes over our web archives.
What can we look for? #
However, we do process our archives in order to index the text from the resources. As each format stores text differently, we have to perform different processes to extract the text from HTML versus, say, a PDF or Office document. Therefore, we have to identify the format of each one in order to determine how to get at the text.
In fact, to help us understand our content, we run two different identification tools, Apache Tika and DROID. The former identifies the general format, and is a necessary part of text extraction processes, whereas the latter attempts to perform a more granular identification. For example, it is capable of distinguishing between the different versions of HTML.
Ideally, one would hope that each of these tools would agree on which documents are HTML, and DROID would provide a little additional information concerning the versions of the formats in use. However, it turns out that DROID takes a somewhat stricter view of what HTML should look like, whereas Tika is a little more forgiving of HTML content that strays further away from standard usage. Another way to look at this is to say that DROID attempts to partially validate the first part of an HTML page, and so those documents that Tika identifies as HTML, but DROID does not, forms a reasonable estimate of the lower-bound of the percentage of invalid HTML in the collection.
Results #
Based on two thirds of our 1996-2010 collection (a randomly-selected subset containing 1.7 billion of about 2.5 billion resources hosted from *.uk), we’ve determined the DROID ‘misses’ as a percentage of the Tika ‘hits’ for HTML, year by year, here:
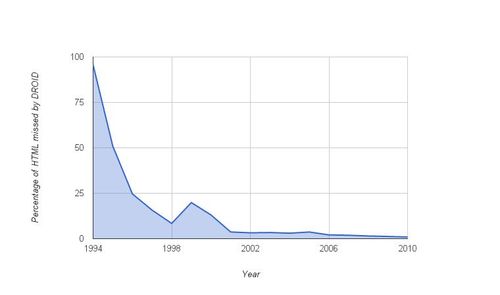
From there one can see that pre-2000, at least ten percent of the archived HTML is so malformed that it’s difficult to even identify it as being HTML. For 1995, the percentage rises to 95%, with only 5% of the HTML being identified as such by DROID (although note that the 1995 data only contains a few hundred resources). Post-2000 the fraction of ‘misses’ has dropped significantly and as of 2010 appears to be around 1%.
What next? #
While it is certainly good news that we can reliably identify 99% of the HTML on the contemporary web, neither Tika nor DROID perform proper validation, and the larger question goes unanswered. While 1% of the current web is certainly invalid, we know from experience that the actual percentage is likely to be much higher. The crucial point, however, is that it remains unclear whether full, formal validity actually matters. As long as we can extract the text and metadata, we can ensure the content can be found and viewed, whether it is technically valid or not.
Although the utility of validation is not yet certain, we will still consider adding HTML validation to future iterations of our indexing toolkit. We may only pass a smaller random-selected sample of the HTML through that costly process, as this would still allow us to understand how much content has the clarity of formal validation, and thus how important the W3C (and the standards it promotes) are to the UK web. Perhaps it will tell us something interesting about standard adoption and format dynamics over time.
Written by Andy Jackson, Web Archiving Technical Lead, The British Library